In SQL Server we have the ability to use temp tables to perform data transformation kind of activities within a stored procedure. As SQL Server evolved table variables were introduced, it is a hotly debated topic when it comes to temp table and table variables which is better. Recently there was a discussion regarding the same, the views were from either camps were solid. Here is a link to the discussion, i did not want to just recreate it here since the folks involved in this topic are very seasoned professionals.
http://www.linkedin.com/groupAnswers?viewQuestionAndAnswers=&discussionID=88979198&gid=66097&commentID=66364401&goback=%2Enmp_*1_*1_*1_*1_*1_*1&trk=NUS_DISC_Q-subject#commentID_66364401
Another Useful link:
http://www.simple-talk.com/community/blogs/philfactor/archive/2011/10/27/104040.aspx.
Based on reading the discussions and the links, it is best to first understand the requirements of the system and then choose a strategy rather than jump to conclusions.
Monday, January 30, 2012
Wednesday, January 25, 2012
SQL Server 2012-BI
One of the areas that is evolving fast in the SQL Server Space is the BI piece. It started off in SQL Server 2000 with DTS and Microsoft Analysis Services, with the evolution of the BI industry it has transformed into something more powerful in SQL Server 2012. At one point it was all about doing OLAP, building KPI's and reporting from the SSAS cubes, with the introduction of PowerPivot, there are some strong offerings in SQL Server 2012. Currently in the SQL Server 2012 there is a seperate version for Business Intelligence this includes a technology called BISM Tabular. Basically Powerpivot uses a OLAP engine called Vertipaq which is an in-memory,columnar store engine. Here is a comparison between the OLAP/Multidimensional and the Tabular offerings.
MultiDimensional Tabular
Requires Dimensional Model Does Not Require Multidimensional Model
MDX-More Advanced Calculations Uses DAX (PowerPivot uses DAX)
OLAP Engine Vertipaq (In-memory,Columnar Store)
MDX language enables Great Performance for point-in-time snapshot analysis.
very advanced calculations
PowerPivot Web Site: http://www.powerpivot.com/
I once had the opportunity of seeing a demo of PowerPivot on a SSD Laptop at a SQL Saturday event. The performance was very impressive, i guess BI tabular option will compliment the OLAP piece very well and will be welcomed by Power users.
MultiDimensional Tabular
Requires Dimensional Model Does Not Require Multidimensional Model
MDX-More Advanced Calculations Uses DAX (PowerPivot uses DAX)
OLAP Engine Vertipaq (In-memory,Columnar Store)
MDX language enables Great Performance for point-in-time snapshot analysis.
very advanced calculations
PowerPivot Web Site: http://www.powerpivot.com/
I once had the opportunity of seeing a demo of PowerPivot on a SSD Laptop at a SQL Saturday event. The performance was very impressive, i guess BI tabular option will compliment the OLAP piece very well and will be welcomed by Power users.
Monday, January 23, 2012
SSRS Tablix...
Recently came across a situation where i had developed a report and there was no rows being returned from the dataset. On investigating i found that for the parameters passed to the stored procedure, the stored procedure would not return any rows. When the report was being displayed it was blank, the user wanted some kind of message to be shown on the screen to indicate that no data is available. I went about researching this issue and found that there are a couple of ways to handle this issue. One is look in the properties of the tablix, there is a NoRows Section, in the section there is a attribute called NoRows Message, this attributes allows one to specify the message to display in the data region when there is no rows of data available.
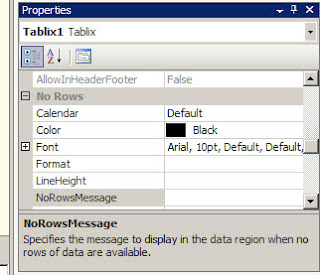 Here one can fill in the message to be displayed and this message will show up when the report is run and there is no data available.
Here one can fill in the message to be displayed and this message will show up when the report is run and there is no data available.
 There is also a blog write up from Jen McCown who owns the site MidnightDBA.com/Jen who suggests a different method for handling the no rows for a dataset situation in the following link.
There is also a blog write up from Jen McCown who owns the site MidnightDBA.com/Jen who suggests a different method for handling the no rows for a dataset situation in the following link.
http://www.midnightdba.com/Jen/2012/01/ssrs-tip-hide-a-tablix-if-no-rows-returned/


http://www.midnightdba.com/Jen/2012/01/ssrs-tip-hide-a-tablix-if-no-rows-returned/
Wednesday, January 18, 2012
SSRS Excel Sheet Naming...
In SSRS 2008, reports could be exported to excel other than this there was no control on how to name the sheets in excel which could provide for better documentation. In the SQL Server 2008 R2/SSRS there is an option to name the sheets in Excel. This provides for better description of the data in the sheets and allows one to break up the data across different sheets. Let us say that the SSRS report displayed sales numbers based on different regions. The report has a row group called regions, there is an attribute called PageName for the group that can be set.
 In the Pagename attribute one needs to select the field name called regions, the value for the PageName attribute would be like =Fields!Region.Value
In the Pagename attribute one needs to select the field name called regions, the value for the PageName attribute would be like =Fields!Region.Value
 Once this is set when the report is exported to excel, the sheets have the region name, each sheet will be named based on the distinct region value.
Once this is set when the report is exported to excel, the sheets have the region name, each sheet will be named based on the distinct region value.


Wednesday, January 11, 2012
SSRS Dynamic Reports...
Recently I was participating in a training class where we were working on SSRS and explaining features to developers who were new to SSRS. A developer raised question, how can one generate dynamic reports in SSRS, on further discussion the scenario was to have a datagrid like control in SSRS. In the .NET framework one can use datagrid and bind it to a Stored procedure and generate dynamic reports. In SSRS one uses dataset and a table/matrix control to build reports. I decided to breakdown the question into different types of dynamic reports in SSRS. The first type of dynamic report is using Matrix Control in SSRS, where in there is a column defined in the Matrix report which can take multiple values. For example take the case of metrics across different calendar years from 2008 to 2011. The matrix report would look like this.


When the year is passed as a parameter the year columns would be dynamic based on the criteria. For example when 2008 is passed as a year then display only 2008, when 2009 is passed as a year display both 2008 and 2009.
In case of a Matrix report the report is dynamic in terms of the values available for a column. Moving on to other type of dynamic reports where the columns itself are dynamic, the approach has to be changed. One of the strategies is to use a table driven approach where in there is a table called tblreportcolumns in the sqlserver database which holds all the possible columns that could be generated for a report. Here let us say we have a stored procedure say usp_gendynamicreport which takes in a parameter, based on different parameter values different columns are returned. On the SSRS side one has to use expressions to show and hide the required columns based on the parameter passed to the stored procedure.
The expression for each column would be something to the effect like:
//For First Column
=IIF(InStr( Fields!NumRows.Value,"a")=0,True,False)
//For Second Column
=IIF(InStr( Fields!NumRows.Value,"b")=0,True,False)
For more details on this approach, one can get to this article:
http://www.codeproject.com/KB/reporting-services/DynamicReport.aspx#
The next approach to creating dynamic reports is to use the approach described in the following link, here the dynamic reports are created using C#/.NET framework, this approach gives a pretty sophisticated dynamic report solution.
http://www.codeproject.com/KB/reporting-services/DynamicReports.aspx


When the year is passed as a parameter the year columns would be dynamic based on the criteria. For example when 2008 is passed as a year then display only 2008, when 2009 is passed as a year display both 2008 and 2009.
In case of a Matrix report the report is dynamic in terms of the values available for a column. Moving on to other type of dynamic reports where the columns itself are dynamic, the approach has to be changed. One of the strategies is to use a table driven approach where in there is a table called tblreportcolumns in the sqlserver database which holds all the possible columns that could be generated for a report. Here let us say we have a stored procedure say usp_gendynamicreport which takes in a parameter, based on different parameter values different columns are returned. On the SSRS side one has to use expressions to show and hide the required columns based on the parameter passed to the stored procedure.
The expression for each column would be something to the effect like:
//For First Column
=IIF(InStr( Fields!NumRows.Value,"a")=0,True,False)
//For Second Column
=IIF(InStr( Fields!NumRows.Value,"b")=0,True,False)
For more details on this approach, one can get to this article:
http://www.codeproject.com/KB/reporting-services/DynamicReport.aspx#
The next approach to creating dynamic reports is to use the approach described in the following link, here the dynamic reports are created using C#/.NET framework, this approach gives a pretty sophisticated dynamic report solution.
http://www.codeproject.com/KB/reporting-services/DynamicReports.aspx
Monday, January 9, 2012
Hadoop Vs ETL...
I recently came across an article referenced in sqlservercentral.com which talks about Hadoop and ETL. The article focuses on some of the misconceptions surrounding how Hadoop might replace ETL. Hadoop and ETL are complimentary to each other since each have their own space. Please refer to the article here:
http://blogs.computerworlduk.com/idc-insight/2012/01/the-rise-of-hadoop-is-etl-dead/index.htm. The article very nicely lists the pros and cons of hadoop at a high level, also how ETL is here to enable datawarehouses which handle structured data.
http://blogs.computerworlduk.com/idc-insight/2012/01/the-rise-of-hadoop-is-etl-dead/index.htm. The article very nicely lists the pros and cons of hadoop at a high level, also how ETL is here to enable datawarehouses which handle structured data.
Tuesday, January 3, 2012
SSAS Processing-SSIS
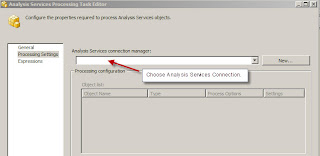
SSIS has a component to process SSAS cubes, it is called the Analysis Services Processing task. This task allows one to specify the cubes/measures groups that need to be processed. This task requires a connection string, the connection string specifies the Analysis services databases that need to be connected to. In the properties of the Analysis Services Processing task, there is a property called ConnectionName, this has the connection name alias for the connection string. The main aspect of this task to process a SSAS cube, there are two ways of specifying the cube. The first method is to use the user interface to specify the cube, this can be done by choosing Edit on the task. In the task editor, specify the Analysis services connection manager, once that is done, in the next step choose the Add button in the Object list window.
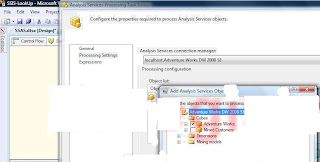 In this example i connected to the Adventure works cube on Analysis services, one can see the list of cubes and the measure groups within the cube. Choose the cube that needs to be processed, the cubes gets added to the Object list window. Once this is done choose OK and the task can be executed to process the cube.
In this example i connected to the Adventure works cube on Analysis services, one can see the list of cubes and the measure groups within the cube. Choose the cube that needs to be processed, the cubes gets added to the Object list window. Once this is done choose OK and the task can be executed to process the cube.

The second method is to use Expressions, within this property there is an attribute called ProcessingCommand. To take advantage of this attribute, create a string variable called sProcess at the package level. An XMLA command can be assigned to this variable. XMLA is a XML string which caters to the processing of SSAS cubes. The XMLA string for the processing of the cube can be generated by going into the SQL Server Management studio, connecting to Analysis services. Select the cube within the Analysis Services database and right click process, the process window comes up. In this window choose the script option and copy the script to a new query window.
 Switch back to SSIS, choose the variable sProcess, copy and paste the XMLA string into the variable. One word of caution is to make sure that the whole process string gets pasted, if this doesn't happen remove the carriage returns and then paste it.
Switch back to SSIS, choose the variable sProcess, copy and paste the XMLA string into the variable. One word of caution is to make sure that the whole process string gets pasted, if this doesn't happen remove the carriage returns and then paste it.
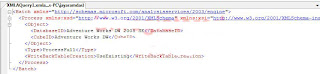
Once this operation is complete, choose the ProcessingCommand property with the Expressions for this task and then assign the variable sProcess, evaluate the expression, one should be able to see the XMLA string. On completion of the expressions execute the task, the SSAS cube will get processed. Using a variable and XMLA one can automate the processing of SSAS cubes and since the XMLA is stored in a string variable, this can be built up by concatenating different string variables.


The second method is to use Expressions, within this property there is an attribute called ProcessingCommand. To take advantage of this attribute, create a string variable called sProcess at the package level. An XMLA command can be assigned to this variable. XMLA is a XML string which caters to the processing of SSAS cubes. The XMLA string for the processing of the cube can be generated by going into the SQL Server Management studio, connecting to Analysis services. Select the cube within the Analysis Services database and right click process, the process window comes up. In this window choose the script option and copy the script to a new query window.


Monday, January 2, 2012
SSIS-Surrogate Key Manangement...
I had discussed different types of dimensions in my earlier posts. One of the aspects which is involved in ETL/Data warehouse building is the use of Surrogate keys. When data is pulled from source systems there are natural keys which are available. In a data warehouse building environment surrogate keys are used in addition to natural keys from the source systems. The reason for using surrogate keys in data warehousing is because data can originate from different systems, the use of surrogate keys enables one to maintain consistency in the data warehouse and these keys can be used to join dimension tables and fact tables. One of the common ways to generate surrogate keys is the use of IDENTITY columns. This would work as long as the amount of data is limited, the moment the data starts to scale and there could be issues with using the IDENTITY column approach. There are vendors who offer SSIS components which take care of surrogate key management. Pragmaticworks offers a product called Task factory, one of the components available is called Dimension Merge SCD Transform (v2.0), this component has in built Surrogate key management. Here is a link for the product: http://pragmaticworks.com/Products/Business-Intelligence/TaskFactory/Features.aspx. One could come up with Custom solutions based on the business needs.
Subscribe to:
Posts (Atom)