In continuation with my earlier blog post of type 1 and type 2 dimensions, there is a third type called the type 3 dimension. The type 3 dimension has limited history preservation in the sense that the history of data is maintained by adding new columns to store historical information. For example if we were to take the example of Manager/Employee as mentioned in y earlier blog post of Type 1 and Type 2, one would have a column called previous endate and a new column called current endate. With this type of construct only the previous history is maintained. I have used a supplier record as an example here.
Supp_Key Sup_Code Supp_Name Start Date Orig_State Curr_State
123 ABC Emp1 22-Dec-2004 TX CA
Employee/Manager Example:
Emp_id Emp_Name Start_Date Orig_Manager_id Current_Mgr_id
235 Emp1 02 Jan 2011 45 55
As one can see in the above schemas it is possible to track only the previous change.
In situations like a Call center when the Structure under a Team manager is dynamic, this would cause lot of additional columns being added to track every change, thus making the table wider and hard to maintain. Type 3 dimensions would find usage where historical changes are limited and the dimension itself is not very volatile.
On a different note, the New Year promises to bring more changes in the area of BigData,Cloud Computing and Social Network/Interactions. It will be interesting to see how the SQL Server EcoSystem adapts/innovates in the above mentioned areas.
I would like to wish all the readers of my blog and everyone a happy and prosperous New Year 2012.
Wednesday, December 28, 2011
Tuesday, December 27, 2011
OLAP basics...
One of the most important aspects of Datawarehousing/Business Intelligence is the aspect of Online Analytical Processing. The key aspects of OLAP are as follows:
Long transactions
Complex queries
Touch large portions of the data
Infrequent updates - Typically in OLAP solutions the data is primarily used for analysis but certain technologies do allow write backs/updates to Cubes. One of the tools which i have worked on which allows such a feature is in Hyperion Essbase where in certain financial cubes one would have the ability to update data in the cube, for example the situation would involve updating budgets for months in a year.
A cube is also known as Multidimensional OLAP. The components of a cube involves the following.
Dimension data forms axes of “cube”
Fact (dependent) data in cells
Aggregated data on sides, edges, corner.
 The above aspects of a cube would help one understand and write better MDX queries which can be typically written to access data from a SSAS cube.
The above aspects of a cube would help one understand and write better MDX queries which can be typically written to access data from a SSAS cube.
There are SQL constructs which would allow one to write queries to examine data, these are provided by the WITH ROLLUP and WITH CUBE constructs.
Here is a Sample Query:
Select dim-attrs, aggrtes
From tables
where conditions
Group By dim-attrs With Cube, this would add to result: faces, edges, and corner of cube using NULL values.
Long transactions
Complex queries
Touch large portions of the data
Infrequent updates - Typically in OLAP solutions the data is primarily used for analysis but certain technologies do allow write backs/updates to Cubes. One of the tools which i have worked on which allows such a feature is in Hyperion Essbase where in certain financial cubes one would have the ability to update data in the cube, for example the situation would involve updating budgets for months in a year.
A cube is also known as Multidimensional OLAP. The components of a cube involves the following.
Dimension data forms axes of “cube”
Fact (dependent) data in cells
Aggregated data on sides, edges, corner.

There are SQL constructs which would allow one to write queries to examine data, these are provided by the WITH ROLLUP and WITH CUBE constructs.
Here is a Sample Query:
Select dim-attrs, aggrtes
From tables
where conditions
Group By dim-attrs With Cube, this would add to result: faces, edges, and corner of cube using NULL values.
Tuesday, December 20, 2011
SSIS-sysssispackages...
I am working on a project where there are lot of ssis packages that need to be converted to SSIS 2008. One of the steps involved in the project is to test the SSIS packages after conversion. In order to test the SSIS packages, the QA folks had to come up with test cases for the SSIS packages, this involved open each SSIS package and identifying areas that need to be checked. It was becoming quite tedious to open and close SSIS packages, at this juncture one of my colleagues suggested a different method to look into the SQL Statements within the SSIS packages. This involved utilising the table sysssispackages which is in the msdb database. The table has columns like Name (SSIS package Name),PackageFormat,PackageType, a complete list of columns is available on Books Online. The column we were interested is called PackageData, this is stored as image in the table. In order to get meaningful information from the PackageData column, the data in the column had to be converted to VARBINARY and then to XML. Here is the query:
SELECT Name, CONVERT(xml,CONVERT(varbinary(max),PackageData)) AS PackageSource
FROM msdb.dbo.sysssispackages
The query produces result like the following:
 I have masked the names of the SSIS packages due to confidentiality, as one can see a hyperlink XML data in the Column named PackageSource. In order to completly view the XML one has to click on the link. This action will open up a new tab within SSMS and the complete XML of the package can be viewed. In this document one can then perform regular string searches to locate SQL statements. We are still working on how effective this approach would be in comparison with opening and closing each SSIS package in the context of searching for SQL statements. I just want to share with you as how to decrypt the PackageData Column.
I have masked the names of the SSIS packages due to confidentiality, as one can see a hyperlink XML data in the Column named PackageSource. In order to completly view the XML one has to click on the link. This action will open up a new tab within SSMS and the complete XML of the package can be viewed. In this document one can then perform regular string searches to locate SQL statements. We are still working on how effective this approach would be in comparison with opening and closing each SSIS package in the context of searching for SQL statements. I just want to share with you as how to decrypt the PackageData Column.
SELECT Name, CONVERT(xml,CONVERT(varbinary(max),PackageData)) AS PackageSource
FROM msdb.dbo.sysssispackages
The query produces result like the following:

Thursday, December 15, 2011
SSIS-Fast Load
In SSIS, as part of the data flow the OLE DB Destination Component is used to insert records into a table in a SQL Server database. There quite a few strategies that can be adopted while loading data into a table.
In the OLEDB Destination Component properties there are different AccessMode, one of them is called OpenRowSet Using Fast Load option. When this option is set one gets to work with other FastLoad Properties such as:
FastLoadKeepIdentity
FastLoadKeepNulls
FastLoadOptions
FastLoadMaxInsertCommitSize
When doing a Fastload, the FastLoadMaxInsertCommitSize is Set to 0, this means that the insert into a table is done has one transaction and then a Commit is applied for the transaction. The reason why this value has to be managed is because when the number of rows being inserted are huge (say a million/millions), it would be wise to break up the transaction into a smaller number of rows per insert. The other reason for having smaller transactions is also being able to manage the log effectively. There is also a note from MSDN noted below:
From MSDN:
A value of 0 might cause the running package to stop responding if the OLE DB destination and another data flow component are updating the same source table.
To prevent the package from stopping, set the Maximum insert commit size option to 2147483647.
In Summary, while using FastLoad option one needs to aware of what kind of load is being performed in terms of number of records and then tune the fast load options to work effectively.
In the OLEDB Destination Component properties there are different AccessMode, one of them is called OpenRowSet Using Fast Load option. When this option is set one gets to work with other FastLoad Properties such as:
FastLoadKeepIdentity
FastLoadKeepNulls
FastLoadOptions
FastLoadMaxInsertCommitSize
When doing a Fastload, the FastLoadMaxInsertCommitSize is Set to 0, this means that the insert into a table is done has one transaction and then a Commit is applied for the transaction. The reason why this value has to be managed is because when the number of rows being inserted are huge (say a million/millions), it would be wise to break up the transaction into a smaller number of rows per insert. The other reason for having smaller transactions is also being able to manage the log effectively. There is also a note from MSDN noted below:
From MSDN:
A value of 0 might cause the running package to stop responding if the OLE DB destination and another data flow component are updating the same source table.
To prevent the package from stopping, set the Maximum insert commit size option to 2147483647.
In Summary, while using FastLoad option one needs to aware of what kind of load is being performed in terms of number of records and then tune the fast load options to work effectively.
Monday, December 12, 2011
SSIS-SCD Type 1 & Type 2
One of the important tasks in an ETL process which supports a Datawarehouse/DataMart is to load data into dimension tables. As per Kimball methodology there are three types of Dimensions like type 1, type 2 and type 3. The most discussed and often implemented is the Type 1 and Type 2 Dimensions. To get a quick overview of the two types: Type 1 dimensions are usually static, in case there are updates the old values are just overwritten. In case Type 2 or slowly changing dimension there is usually a historical record of what changed in the Dimension. A good example of this could agents working for a Team Manager in a Call center. A agent could have his Team Manager re-assigned and this change would have to captured in the data mart and that is where Type 2 dimensions come in. In SSIS in order to facilitate the loads of Type 1 and Type 2 dimensions, we have the SCD wizard which can be used. On walking through the wizard, one can set up Changing attributes and Historical attributes. Once this task is finished, a data flow is generated to handle Type 1 and Type 2 Dimension loading. In the image below one can notice the OLE DB Command Component being used by SCD component.
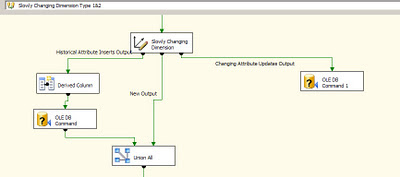
As it has been discussed in a lot of articles,blogs, the SCD component does not scale very well. There have been performance issues with using the SCD component straight out of the box. One of reasons could be the fact that the SCD component uses the OLE DB Command component to perform updates of rows, these rows are updated one row at a time. The time to update the rows can significantly increase if there are a lot of changes that are to be processed. In fact even while performing incremental inserts or updates to tables in general OLE DB command component can take up quite a bit of time in order to process the rows.
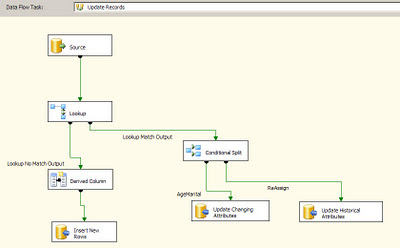
One of the methods to alleviate performance is to use a temporary/staging table where in all the changes are loaded in the destination database. Once this data flow is complete, use a stored procedure to merge the changes into the actual destination table. In the Stored procedure one could take advantage of the MERGE T-SQL command to insert/update records into the destination table by using the temporary/staging table. In the image below one can notice that the OLE DB Command component has been replaced by the OLE DB Destination component.


As it has been discussed in a lot of articles,blogs, the SCD component does not scale very well. There have been performance issues with using the SCD component straight out of the box. One of reasons could be the fact that the SCD component uses the OLE DB Command component to perform updates of rows, these rows are updated one row at a time. The time to update the rows can significantly increase if there are a lot of changes that are to be processed. In fact even while performing incremental inserts or updates to tables in general OLE DB command component can take up quite a bit of time in order to process the rows.
One of the methods to alleviate performance is to use a temporary/staging table where in all the changes are loaded in the destination database. Once this data flow is complete, use a stored procedure to merge the changes into the actual destination table. In the Stored procedure one could take advantage of the MERGE T-SQL command to insert/update records into the destination table by using the temporary/staging table. In the image below one can notice that the OLE DB Command component has been replaced by the OLE DB Destination component.

To finish this up, in the contro flow we would have a Execute SQL task to perform the Merge operation. Here is a visual of the Flow.

Monday, December 5, 2011
BigData,NoSQL...
In the recent couple of years there has been steady development in areas of non-relational data storage, where in the data does not fit into a more orderly schema instead the data tends to have flexible schema. These center around the recent developments in social media and social networking where in enormous amounts of data is being stored and retrieved. Since the vendors/companies in social networking space did not find traditional RDBMS to suit their needs, the emergence of NoSQL systems took place. NoSQL means "Not only SQL". These systems (NoSQL) have flexible schema,Massive scalability (since lot of requests can be handled in parallel) and higher performance and availability. There are different implementations of NoSQL Systems, they are:
1. MapReduce FrameWork.
2. Key-Value Stores
Example Systems: Google BigTable,Amazon Dynamo,Cassandra.
3. Document Stores.
Example Systems: CouchDB,MongoDB,SimpleDB.
4. Graph Database Systems.
Example Systems: Neo4j,FlockDB,Pregel.
The MapReduce Framework is kind of analogous to OLAP in the Business Intelligence world, the Key-Value Stores can be kind of analogous to the OLTP world. Document Stores use a Key,Document pair to persist documents and also enables faster retrieval of documents, one of the popular systems which implements Document Store is MongoDB.
One of the popular implementation of NoSQL system is the MapReduce Framework which was originally developed in Google, then followed by the Open Source implementation called Hadoop. This Map Reduce has No Data model, the data is stored in files on the Google File System (GFS) or the Hadoop file System called HDFS. There are specific functions in this Framework such as Map(),Reduce(),Reader(),Writer() and Combiner(). Microsoft has plans to work with Hadoop in some form, the NoSQL has been gaining traction in the last couple of years and this space is bound to see a lot of changes in the coming years. I would to thank Prof. Jennifer Widom (Stanford University, Computer Science) for providing information/material on NoSQL Systems as part of a online course in database systems.
1. MapReduce FrameWork.
2. Key-Value Stores
Example Systems: Google BigTable,Amazon Dynamo,Cassandra.
3. Document Stores.
Example Systems: CouchDB,MongoDB,SimpleDB.
4. Graph Database Systems.
Example Systems: Neo4j,FlockDB,Pregel.
The MapReduce Framework is kind of analogous to OLAP in the Business Intelligence world, the Key-Value Stores can be kind of analogous to the OLTP world. Document Stores use a Key,Document pair to persist documents and also enables faster retrieval of documents, one of the popular systems which implements Document Store is MongoDB.
One of the popular implementation of NoSQL system is the MapReduce Framework which was originally developed in Google, then followed by the Open Source implementation called Hadoop. This Map Reduce has No Data model, the data is stored in files on the Google File System (GFS) or the Hadoop file System called HDFS. There are specific functions in this Framework such as Map(),Reduce(),Reader(),Writer() and Combiner(). Microsoft has plans to work with Hadoop in some form, the NoSQL has been gaining traction in the last couple of years and this space is bound to see a lot of changes in the coming years. I would to thank Prof. Jennifer Widom (Stanford University, Computer Science) for providing information/material on NoSQL Systems as part of a online course in database systems.
Friday, December 2, 2011
Visual Studio 2010-SQL
Recently I started using Visual Studio 2010 Professional Version. There are lot of new features in VS 2010 which goes without saying. One of the areas which i frequently work on is databases. There is a lot of integration between VS 2010 and the upcoming SQL Server 2012 version. Once a connection is established to a SQL Server using the server explorer, one can view the objects within the database in the server explorer. In the menu option Data when you choose Transact-SQL Editor, at first you are asked to log in to SQL Server, once logged in the query window opens up just like the one in SQL Server Management studio. There is a option Database next to which one can see the current database you are connected to. This feature comes in handy when there is development going on in a VS 2010 environment and at the same data needs to be explored. The integration between VS 2010 and SSMS seems very close in VS 2010.

When a query is written, it can highlighted and when the right click on the mouse is pressed, one can see a popup menu being displayed.


When a query is written, it can highlighted and when the right click on the mouse is pressed, one can see a popup menu being displayed.

Wednesday, November 30, 2011
SSIS LookUp Task...
In SSIS one of the tasks used for incremental data loading/updating is Lookup task, of course depending on the scenario. In the look up task one of the properties/settings that can be customized is the cache mode. A good understanding of the cache mode helps one design better packages utilising lookup tasks. Here is an article though published in 2008 gives a very good insight into the different cache modes. This article is by Matt Masson,http://blogs.msdn.com/b/mattm/archive/2008/10/18/lookup-cache-modes.aspx. It breaks down different cache modes and explains the use of each of them.
Monday, November 21, 2011
Isolation Levels...
When working with a relational database management system , it is very important to understand the concept of isolation levels. The isolation levels become even more important while working on transactional database systems. The isolation levels might seem very basic but it effects are more paramount as one starts to view the big picture especially a critical transactional database. It is very important to provide consistency and concurrency for the users of the transactional system. There are some basic isolation levels which are provided in SQL Server:
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITEDSET TRANSACTION ISOLATION LEVEL READ COMMITED (the default setting in SQL Server)SET
SET
There are some newer isolation levels provided in more recent versions of SQL Server. I visted a older article but very relevant as one dealing with transactions, here is the link: The article has been written by Kalen Delaney, she is a sql server expert:http://www.sqlmag.com/article/tsql3/transaction-isolation-levels
I would encourage one to try out the examples in the article, it gives a good understanding of how isolation works. TRANSACTION ISOLATION LEVEL SERIALIZABLE. TRANSACTION ISOLATION LEVEL REPEATABLE READ
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITEDSET TRANSACTION ISOLATION LEVEL READ COMMITED (the default setting in SQL Server)SET
SET
There are some newer isolation levels provided in more recent versions of SQL Server. I visted a older article but very relevant as one dealing with transactions, here is the link: The article has been written by Kalen Delaney, she is a sql server expert:http://www.sqlmag.com/article/tsql3/transaction-isolation-levels
I would encourage one to try out the examples in the article, it gives a good understanding of how isolation works. TRANSACTION ISOLATION LEVEL SERIALIZABLE. TRANSACTION ISOLATION LEVEL REPEATABLE READ
Tuesday, November 15, 2011
Database Master
The main tool i typically use is the SQL Server Management studio for working with queries. Recently i came across a tool which i needed since i had to work with SQLLite/MySql databases. The name of the tool is called Database Master which has been developed by Nucleon Software, the web site is http://www.nucleonsoftware.com/. The software is available for download with a 30 day free trail. One of the neat things about this tool is the ability to connect to variety of data sources, they include MongoDB, a document based database,
SQL Server,Oracle,MySQL,PostgreSQL,SQLLite,Netezza,db2,Ingres,dbase,XML,Firebird,Foxpro and dbase. As one can see that this is a pretty exhaustive list of databases. Once a connection profile is established, it provides a Object Explorer/query window type interface just like the one in SSMS. It is a pretty light weight tool. The tool has options for working on LINQ based qery as well. There is a snapshot of the UI given below.

One of the USP of this tool is the ability to connect to a variety of data sources, i found this useful in my ETL project where i need to connect to a variety of data sources and need to examine the data.
SQL Server,Oracle,MySQL,PostgreSQL,SQLLite,Netezza,db2,Ingres,dbase,XML,Firebird,Foxpro and dbase. As one can see that this is a pretty exhaustive list of databases. Once a connection profile is established, it provides a Object Explorer/query window type interface just like the one in SSMS. It is a pretty light weight tool. The tool has options for working on LINQ based qery as well. There is a snapshot of the UI given below.

Thursday, November 10, 2011
SSIS-Error Messages
There are situations/circumstances where one runs/debugs a SSIS package in the BIDS/Visual studio environment, one would encounter errors. In the progress tab we can see what steps have been performed in the SSIS package and at time we see lenght error messages. The error messages tend to be not visible entirely in the Progress tab. This could make it difficult for one to understand what the message is and proceed with the debugging process. Here is a snapshot of the progress tab within BIDS.
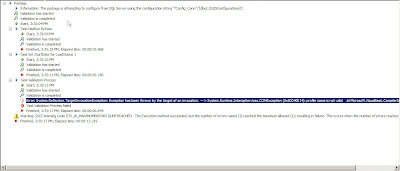 In order to get the full text of the error message , highlight the message and do a right click, the option Copy message text shows up, click on it and one can paste it from the clipboard into a editor like notepad/word to get the full message.
In order to get the full text of the error message , highlight the message and do a right click, the option Copy message text shows up, click on it and one can paste it from the clipboard into a editor like notepad/word to get the full message.

This has helped me in lot of situation when i had to deal with sometimes cryptic error messages.


This has helped me in lot of situation when i had to deal with sometimes cryptic error messages.
Wednesday, November 9, 2011
Ethics & Presentations
In the SQL Server Community today there are lot of presentations being made in conferences, as part of learning and teaching courses. One of the main aspects of presenting to a technical audience such as SQL Server requires adhering to certain discipline and ethics while presenting content. At times i have heard about folks using profanity in presentations to get attention of the crowd or to sell themselves as very cool in front of audience, well this doesn't work in a technical audience i think. Thanks to http://www.sqlservercentral.com/, i am posting a link to Scott Hanselman's blog:
http://www.hanselman.com/blog/ProfanityDoesntWork.aspx
I felt that the content presented here is very relevant and brings out good points on what needs to be and what needs to be avoided in presentations.Hope this provides an enjoyable read. I feel that one needs to well research the material and be prepared fo questions from the audience. When the content being delivered is good, the audience will be drawn into the speaking event.
http://www.hanselman.com/blog/ProfanityDoesntWork.aspx
I felt that the content presented here is very relevant and brings out good points on what needs to be and what needs to be avoided in presentations.Hope this provides an enjoyable read. I feel that one needs to well research the material and be prepared fo questions from the audience. When the content being delivered is good, the audience will be drawn into the speaking event.
Thursday, November 3, 2011
XML-XSLT
In continuation with the blog post on XML, there is an another method to extract data from a XML document, the method is XSLT. XSLT is Extensible Style Sheet Language with a Transformation. The XML document is fed to a XSLT processor along with the XSLT file, the XSLT file is applied on the XML document to produce the desired XMl document. A XSLT file has a set of match and replace commands, it is also possible to recursively match and replace using a XSLT file. An XSLT file helps one to produce a more user friendly XML document. In a XSLT file one can also perform loops and iterations which makes XSLT a powerful means of extracting data from a XML Document. Here is a sample XSLT file listed below:
<xsl:stylesheet xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="2.0">
<xsl:output method="xml" indent="yes" omit-xml-declaration="yes" />
<xsl:template match="Textbook[@Price > 90]">
<xsl:copy-of select="."/>
xsl:template>
<xsl:template match="text()" />
<xsl:template match="NewsMagazine">
<xsl:copy-of select="."/>
xsl:template>
xsl:stylesheet>
A sample For each construct in XSLT:
<xsl:for-each select="countries/country">
XSLT Commands...
xsl:for-each>

In the Kernow utility as mentioned in the Previous blog post on XML, one can work with XSLT and run transformations on XML in the XSLT Sandbox tab.
<xsl:stylesheet xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="2.0">
<xsl:output method="xml" indent="yes" omit-xml-declaration="yes" />
<xsl:template match="Textbook[@Price > 90]">
<xsl:copy-of select="."/>
xsl:template>
<xsl:template match="text()" />
<xsl:template match="NewsMagazine">
<xsl:copy-of select="."/>
xsl:template>
xsl:stylesheet>
A sample For each construct in XSLT:
<xsl:for-each select="countries/country">
XSLT Commands...
xsl:for-each>

In the Kernow utility as mentioned in the Previous blog post on XML, one can work with XSLT and run transformations on XML in the XSLT Sandbox tab.
Friday, October 28, 2011
XML-XPath,XQuery
One of the common ways the data is exchanged between applications is XML. XML is a data format , which follows the construct below, a XML document typically has Elements,attributes and a root element , all of which defines the structure of the data. One of the issues/challenges is on how to query the XML data. There are a lot of instances where a certain element/sub-element/attributes of a XML document need to be consumed by other pieces of an application. Here is a snapshot of a XML document.
 There a couple of tools to query a XML document, they are XPath and Xquery. Both Xpath and Xquery allows one to traverse a XML document and returns the required pieces of information from the XML document. There is a tool which is available for download where in one can write interactive XPath and Xquery queries on XML. The tool can be downloaded from http://kernowforsaxon.sourceforge.net/, once the tool is downloaded and installed (the tool requires Java to be present on a laptop/desktop), it is very interactive to use. When one is working with Xpath and Xquery, the queries can be sometimes tough to construct to get the desired result, this tool provides a SQL Server Management studio type experience when writing queries, the query editor does not have intellisense.
There a couple of tools to query a XML document, they are XPath and Xquery. Both Xpath and Xquery allows one to traverse a XML document and returns the required pieces of information from the XML document. There is a tool which is available for download where in one can write interactive XPath and Xquery queries on XML. The tool can be downloaded from http://kernowforsaxon.sourceforge.net/, once the tool is downloaded and installed (the tool requires Java to be present on a laptop/desktop), it is very interactive to use. When one is working with Xpath and Xquery, the queries can be sometimes tough to construct to get the desired result, this tool provides a SQL Server Management studio type experience when writing queries, the query editor does not have intellisense.

Sample Xpath Query:
doc("Bookstore.xml")/Bookstore/Book[Remark]/Title - This Xpath Query works on the XML document "Bookstore.xml" and returns the titles of all the Books which have Remarks.
Xquery is a more powerful implementation of the XPath language, one of the key features in XQuery is the FLOWR expression: The FLOWR expression follows the syntax below:
for $x in doc("Bookstore.xml")/Bookstore/Book
where $x/@Price >= 100
return $x
The expression above has a For Clause which allows one to loop through the XML document based on a given element, then check for a condition, the WHERE clause and then return the result in a XML format which is the return Clause. Here is an another example:
for $x in doc("BookstoreQ.xml")/Bookstore/Book
where $x/@Price < 90
and $x/Authors/Author/Last_Name = "Andrew"
return
{ $x/Title }
The above expression returns a XML with the root element has Book, the titles of all the Books where the Last Name of the Author is Andrew and the Price of the Book is < 90.


Sample Xpath Query:
doc("Bookstore.xml")/Bookstore/Book[Remark]/Title - This Xpath Query works on the XML document "Bookstore.xml" and returns the titles of all the Books which have Remarks.
Xquery is a more powerful implementation of the XPath language, one of the key features in XQuery is the FLOWR expression: The FLOWR expression follows the syntax below:
for $x in doc("Bookstore.xml")/Bookstore/Book
where $x/@Price >= 100
return $x
The expression above has a For Clause which allows one to loop through the XML document based on a given element, then check for a condition, the WHERE clause and then return the result in a XML format which is the return Clause. Here is an another example:
for $x in doc("BookstoreQ.xml")/Bookstore/Book
where $x/@Price < 90
and $x/Authors/Author/Last_Name = "Andrew"
return
{ $x/Title }
The above expression returns a XML with the root element has Book, the titles of all the Books where the Last Name of the Author is Andrew and the Price of the Book is < 90.
Thursday, October 20, 2011
SSIS-Package Configuration
When working with SSIS packages, one of the aspects that need to be designed also is how to lyout the configuration for the Package. This relates to storing certain aspects of the packages like variable values, database connections, flat file/ftp connection information. The are different ways to perform configurations, the one that is being talked about here is using SQL Server Configuration. First when one right clicks on the area of the package in the control flow task, the package configuration shows up, on choosing the user is presented with a wizard. In the Package Configuration organizer window check the Enable package configurations and choose Add...In the Select Configuration Type Window Choose Configuration Type as SQL Server, in the Connection Drop down, the connection should point to the sql server database where the table SSISConfiguration data table is going to reside, next choose the SSIS configuration table, the next one is the configuration filter, this is the one which points to the different variable values, and database connection strings which are going to be used by the package. Here is an image of the Configuration window.
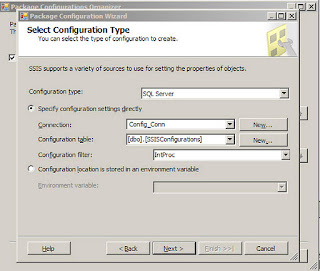 Once the filter is chosen, click on the Next button and choose the properties of the variables that need to be stored in the SSIS Configurations table.
Once the filter is chosen, click on the Next button and choose the properties of the variables that need to be stored in the SSIS Configurations table.
In this example, the Filter Intproc points to the following rows in the SSIS Configurations table. The PackagePath Column has the variable names in the SSIS package, whose values are being stored.
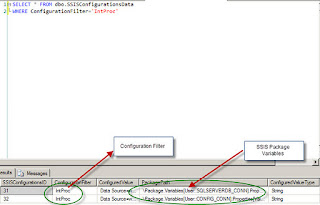

In this example, the Filter Intproc points to the following rows in the SSIS Configurations table. The PackagePath Column has the variable names in the SSIS package, whose values are being stored.

Tuesday, October 11, 2011
SSIS Script Component...
Recently I used a Script Component in the data flow task within SSIS. I decided to use the component has a means to do data transformation. There are lot of different ways to do transformation within SSIS, but i just wanted to check out how SSIS Script component performs. Here is a link to Linkedin MSBI group where i had posted a question on how script component would perform: Lot of folks have suggested different strategies on how to go about the data transformation.
Link:(SSIS Script Component Discussion)
http://www.linkedin.com/groupItem?view=&gid=59185&type=member&item=73910791&qid=20824120-bb37-4de1-ba8b-1d86a23979ea&trk=group_most_popular-0-b-ttl&goback=%2Egmp_59185
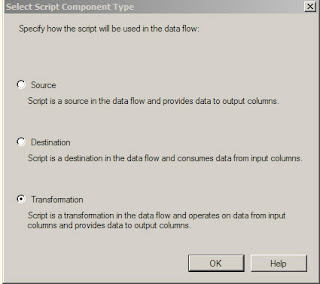
When one drags a script component on to the Data flow task editor, here is the screen dialog that pops up.
Suggested Alternatives for Script Component:
Use T-SQL MERGE operator.
Use Combination of LOOKUP and Conditional Split to figure out new records/changed records.
Use EXECUTE SQL task and call a stored procedure to perform data transformation.
Link:(SSIS Script Component Discussion)
http://www.linkedin.com/groupItem?view=&gid=59185&type=member&item=73910791&qid=20824120-bb37-4de1-ba8b-1d86a23979ea&trk=group_most_popular-0-b-ttl&goback=%2Egmp_59185
When one drags a script component on to the Data flow task editor, here is the screen dialog that pops up.

Suggested Alternatives for Script Component:
Use T-SQL MERGE operator.
Use Combination of LOOKUP and Conditional Split to figure out new records/changed records.
Use EXECUTE SQL task and call a stored procedure to perform data transformation.
Friday, October 7, 2011
SSAS 2008-Perspectives
When creating a cube in SSAS with the fact and dimension tables, it is possible that the Measures in the cube could belong to different parts of business. To elaborate on this , it is possible that the Cube could have Sales related measures, Customer related measures and Product related measures. When the cube is deployed and is being viewed by business users, it is possible that certain business users would like to focus on the measures to their business area. In order to achieve instead of having cubes split into smaller cubes based on business function, there is a feature called Perspectives available in SSAS 2008. Once the cube has been created and related dimensions have been added, the different perspectives can be created. In the screen shot below, the Perspectives tab is highlighted (this is in BIDS/Visual Studio 2008).

In the Perspectives, initially one gets to see the default perspective which is a view of the whole cube with all the measures and all the dimensions. In order to create a new Perspective, one has to click the New Perspective icon nest to the process icon in the toolbar.

First name the new perspective and start working downwards to start choosing/Checking the Measures needed to be shown for this perspective, likewise do the same for the dimensions.
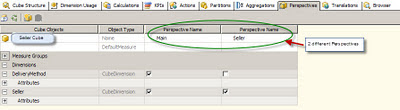
Once this is completed and the cube is processed, the cube data can be viewed in the Browser tab. In the Browser tab one can choose the different perspectives from the Perspectives dropdown and change the data being viewed. Perspective, I think is a neat way to get different views of data in the cube without physically splitting the cube.
In the Perspectives, initially one gets to see the default perspective which is a view of the whole cube with all the measures and all the dimensions. In order to create a new Perspective, one has to click the New Perspective icon nest to the process icon in the toolbar.
First name the new perspective and start working downwards to start choosing/Checking the Measures needed to be shown for this perspective, likewise do the same for the dimensions.

Once this is completed and the cube is processed, the cube data can be viewed in the Browser tab. In the Browser tab one can choose the different perspectives from the Perspectives dropdown and change the data being viewed. Perspective, I think is a neat way to get different views of data in the cube without physically splitting the cube.
Wednesday, October 5, 2011
Union All-SSIS
One of the requirement i had was to combine multiple inputs into one input and then push the data into a table on a sql server database. In the Data Flow Task, there were different components which were sending outputs, all of these outputs had to be combined. In order to address this I used the UNION ALL task in the Data flow. The UNION ALL task can take multiple inputs and can be combined into one. The UNION ALL task does not have too many properties , it is a very simple component which is available in SSIS. I have enclosed a graphic below which shows how it was used in the Data Flow task. The image below shows one input into UNION ALL:

Multiple Inputs:

At times the UNION ALL task can be used to get inputs from different Conditional Split task outputs, this can be used in Testing scenarios to see if the rows are being branched out correctly.

Multiple Inputs:
At times the UNION ALL task can be used to get inputs from different Conditional Split task outputs, this can be used in Testing scenarios to see if the rows are being branched out correctly.
Monday, October 3, 2011
Roles-SSAS
In SSAS cubes one can have security enforced in terms of restricting users as to what they can see in the cube depending upon their business role. The interface has undergone some changes over the different versions of SSAS. In SQL Server 2008, one can start of implementing security for a cube by defining roles. When one opens a Analysis services project, in the solution explorer there is a folder called roles. When one right clicks on the Role folder there is a option to add a new role. This opens up a tabbed interface in visual studio(BIDS). There are different tables to take one through creating a new role and assigning the required permissions. The tabs are General,Membership,DataSources,Cubes,Cell Data,Dimensions,Dimension Data and Mining Structures. In the general tab one assigns a name to the role and selects what kind of permissions is needed, they are three permissions:
Full Control
Process database
Read Definition.
 Once the type of permissions is chosen we can proceed to the membership tab and start adding users to the role. For example if Read Definition was chosen in the first tab, the one can proceed to the other tabs listed above and complete the security requirements.
Once the type of permissions is chosen we can proceed to the membership tab and start adding users to the role. For example if Read Definition was chosen in the first tab, the one can proceed to the other tabs listed above and complete the security requirements.
Full Control
Process database
Read Definition.

Friday, September 30, 2011
Database SnapShots...
I have been working in environments where users/analysts would like to view the state of the records in a database at a particular point in time or would like to analyse values during a particular day. Usually these kind of requests some time come up after the day in question to be analyzed has passed. In order to handle this requirement I suggested the use of database snapshots to do perform analysis. The database snapshots can be used to test performance of queries without affecting the Primary database. The database snapshots in Sql server. Please use the following link to get a understanding of how the database snapshot works in SQL Server. This feature has come in handy for me to allow the users to perform certain adhoc analysis.
The article in the link below has been written by Dinesh Asanka .
http://www.sql-server-performance.com/2008/sql-server-database-snapshot/
Here is a basic syntax for creating a Database Snapshot:
CREATE DATABASE ssAdventureWorks_dbss2230 ON
( NAME = AdventureWorks_Data, FILENAME =
‘C:Program FilesMicrosoft SQL ServerMSSQL.1MSSQLDataAdventureWorks_data_2230.ss’ )
AS SNAPSHOT OF AdventureWorks;
GO
The article in the link below has been written by Dinesh Asanka .
http://www.sql-server-performance.com/2008/sql-server-database-snapshot/
Here is a basic syntax for creating a Database Snapshot:
CREATE DATABASE ssAdventureWorks_dbss2230 ON
( NAME = AdventureWorks_Data, FILENAME =
‘C:Program FilesMicrosoft SQL ServerMSSQL.1MSSQLDataAdventureWorks_data_2230.ss’ )
AS SNAPSHOT OF AdventureWorks;
GO
Wednesday, September 28, 2011
SSRS-Document Map
In SSRS Report Builder 3.0, A document map provides a set of navigational links to report items in a rendered report. When you view a report that includes a document map, a separate side pane appears next to the report. Launch the Report Builder 3.0, open the report file (.rdl). In the .rdl, highlight the tablix control or Matrix Control for which you want create the Document Map. Right Click on Properties for the tablix Control, In the Properties window look for a property called DocumentMapLabel. Provide a Name for the Document Map. For the items in the report that need the DocumentMap, repeat the steps mentioned before. Document Maps would be very handy when reports are complex and wide, the document map would enable the user to navigate to the appropriate areas. Here is a illustration of where the property is:


Once the DocumentMapLable is set for the required items, when the report is run the document map appears on the left hand side of the Report. The Document Map Option above Parameters allows user to Show/Hide the Document Map.

Monday, September 26, 2011
SSIS...
Recently I cam across a vendor who provide SSIS package template generator for different Datawarehousing situations. It allows a developer to specify datasources, then work on choosing the business models. In the business model one has the ability to select the fact and dimension tables. Then the tool works on a generating a SSIS package which adhere to the business model. One can can then view the SSIS packages in Visual studio and edit them if it is needed. The name of the vendor is Leganto, http://www.leganto.com/, they have apps which help the developer in deploying the BI Apps faster. More details,examples can be found on the website.Quote form the website:
Discover Ready To Use BI Apps
Our BI Apps will help you deliver BI Projects
faster, reducing your average data warehouse
development time by up to 60%. Giving you the
tools to make better business decision, faster.
Discover Ready To Use BI Apps
Our BI Apps will help you deliver BI Projects
faster, reducing your average data warehouse
development time by up to 60%. Giving you the
tools to make better business decision, faster.
Tuesday, September 20, 2011
SSIS Multicast...
One of the features available in SSIS data flow tasks is the Multi cast Transform. This allows us to make multiple copies of data which is fed into the Multi cast task. This task takes in a single input and the Multi cast task makes multiple copies of data available as the output, it is like xerox copy machine. Each of the outputs coming out of Multi task transform can be used in different ways in the sense that one output can be sent to a archive database destination, another output could be transformed into other forms of data. One of the uses which i have come across is where we need to push the production data down to different test/development environments, this type of package is really handy for DBA's.


Tuesday, September 13, 2011
List of SSIS Packages...
In this post i wanted to highlight the availability of a standard report which lists all the SSIS packges stored in SQL Server. This report was generated in SQL Server 2005. First Connect to the Integration Services using SSMS 2005, this would bring up the object explorer, in the object exploer expand the Stored packages folder. Under this folder there is a Subfolder called MSDB, right click on the sub folder and select Reports and proceed to select standard reports. Under the Standard reports, choose general. This will generate a standard report as shown below:
The first column displays the extension of the SSIS package, which is dtsx.

The first column displays the extension of the SSIS package, which is dtsx.

Friday, September 9, 2011
Fuzzy Lookup...SSIS...
Recently I was working on a project where in there was a requirement to check the quality of data before uploading the data to SQL Server. There are a couple of tasks in the Data flow component of SSIS which allow one to scrubb the input data. The two tasks which are available are Fuzzy Lookup and Fuzzy grouping tasks. The data source for the SSIS package had a text file which contains a list of contacts that need to be scrubbed and uploaded to the database. The contact text file could have names that are misspelt or have bad characters. As per the business there can certain set of tolerance and confidence level set based on which the misspelt records could be uploaded or rejected. This is where the fuzzy lookup task comes into play. I have enclosed a sample Fuzzy Lookup editor:


In this SSIS package, the records which have a valid lookup contact in the database is sent through the Fuzzy lookup task. The output of fuzzy lookup task can then be directed to a conditional split task. There are certain columns which are in built in the fuzzy lookup that are available to the conditional split task,they are _Similarity and _Confidence. Based on the values of these two variables and business rules records can be inserted or rejected from being uploaded to the database.



In this SSIS package, the records which have a valid lookup contact in the database is sent through the Fuzzy lookup task. The output of fuzzy lookup task can then be directed to a conditional split task. There are certain columns which are in built in the fuzzy lookup that are available to the conditional split task,they are _Similarity and _Confidence. Based on the values of these two variables and business rules records can be inserted or rejected from being uploaded to the database.

Wednesday, September 7, 2011
SQL Server Denali (11)...
There are some neat enhancements in SQL Server Denali with respect to the Data Warehousing/BI spectrum. The SSIS Server is going to be enhanced in a major way, there is going to be Self Service SSRS feature, there is going to be a feature called Column Store which is a new type of index, this feature is expected to accelerate queries in a datawarehouse. There is a project named Apollo where in this feature is discussed in detail. Look for the technical article :
Columnstore Indexes for Fast Data Warehouse Query Processing in SQL Server 11.0.
There has been a set of SQL Server Developer Tools Code Named "Juneau" which has been release by microsoft. Here is a breif description:SQL Server Developer Tools, Codename "Juneau" transforms database development by introducing a ubiquitous, declarative model that spans all the phases of database development and maintenance/update. One can go to the following link to check it out:
http://northamerica.msteched.com/topic/details/DBI376-HOL?fbid=T3Bixb0H50m#showdetails
Columnstore Indexes for Fast Data Warehouse Query Processing in SQL Server 11.0.
There has been a set of SQL Server Developer Tools Code Named "Juneau" which has been release by microsoft. Here is a breif description:SQL Server Developer Tools, Codename "Juneau" transforms database development by introducing a ubiquitous, declarative model that spans all the phases of database development and maintenance/update. One can go to the following link to check it out:
http://northamerica.msteched.com/topic/details/DBI376-HOL?fbid=T3Bixb0H50m#showdetails
Wednesday, August 31, 2011
Loading Mutliple Files (Contd..)
I had mentioned in my previous post on how to handle auditing of multiple files. While auditing the file loads, the name of the file loaded is stored in a sql server table once the data flow is completed successfully.
Within the For Each Loop Container, I added a execute sql task after the data flow task. The execute sql task takes in the user defined variable sFileName and passes it as a parameter to an INSERT statement. This can be modified into a stored procedure in case there need to be more details added about the file loaded. Once the execute sql task runs it inserts the value of the user defined variable into a table. The table can be queried to find out what files have been loaded successfully. I have included the image of the Control Flow below.
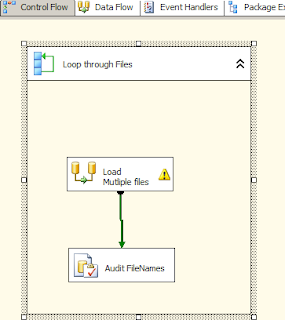 The name of the execute sql task is Audit FileNames.
The name of the execute sql task is Audit FileNames.
Within the For Each Loop Container, I added a execute sql task after the data flow task. The execute sql task takes in the user defined variable sFileName and passes it as a parameter to an INSERT statement. This can be modified into a stored procedure in case there need to be more details added about the file loaded. Once the execute sql task runs it inserts the value of the user defined variable into a table. The table can be queried to find out what files have been loaded successfully. I have included the image of the Control Flow below.

Monday, August 29, 2011
Loading Multiple files...
Recently I came across a scenario where in i had to load multiple excel files into a database table in sql server.The excel files reside in a folder from where these files need to be loaded into a sql server table. At first i worked on the data flow task where i import one excel file into the table. The reason being i need to build out the connection string for the excel source. I dragged a Excel source to the data flow task editor and a OLE Db destination data source. I set the source folder and the file for the excel source and also choose the first row has column names option.

This sets the connection for the excel source like this:
Provider=Microsoft.Jet.OLEDB.4.0;Data Source=C:\Ramdas\SSIS\Sheet1.xls ;Extended Properties="EXCEL 8.0;HDR=YES";
Once the excel source is set, connect it to the destination and do the required mappings for the destination table. Test the data flow task to make sure the data from a single excel can be imported.
In the Control flow editor, create a string variable called sfilename of type string and set the value of this to the excel file with the path (In this example: "C:\Ramdas\SSIS\Sheet1.xls), make sure the scope of the variable is at the package level.

Drag an For Each Loop Container, make sure the data flow task is inside the container. Edit the For Each Loop Container, choose the ForEach file enumerator in the Collection window, choose the file path and choose the option Full qualified under retrieve file name. In the variables section choose the variable sFilename and set the index to 0.

In the Data Flow task editor, right click on the Excel Connection Manager,Choose Properties, within the properties choose Expressions. In the Expressions dropdown Choose connection string. In the expression editor window copy and paste the Connection String of Excel connection manager, replace the fully qualified name with the user defined variable. The expression should be like the following:
"Provider=Microsoft.Jet.OLEDB.4.0;Data Source=" + @[User::sFilename]+" ;Extended Properties=\"Excel 8.0;HDR=YES\";"

The backslash in this expression is critical since they are the escape characters. When the evaluate expression is clicked the following statement should appear:
Provider=Microsoft.Jet.OLEDB.4.0;Data Source=C:\Ramdas\SSIS\Sheet1.xls ;Extended Properties="Excel 8.0;HDR=YES";
Once the expression is tested, click ok.
Now going back to the Control Flow the ForEach Container can be executed and multiple files within the source folder would be loaded to the database. In order to make sure that multiple files are loaded one can create an other table in the sql server database and capture the value in the user defined variable into a table.
I would like to thank the author of the blog,Matthew Roche: http:\\bi-polar23.blogspot.com.

This sets the connection for the excel source like this:
Provider=Microsoft.Jet.OLEDB.4.0;Data Source=C:\Ramdas\SSIS\Sheet1.xls ;Extended Properties="EXCEL 8.0;HDR=YES";
Once the excel source is set, connect it to the destination and do the required mappings for the destination table. Test the data flow task to make sure the data from a single excel can be imported.
In the Control flow editor, create a string variable called sfilename of type string and set the value of this to the excel file with the path (In this example: "C:\Ramdas\SSIS\Sheet1.xls), make sure the scope of the variable is at the package level.

Drag an For Each Loop Container, make sure the data flow task is inside the container. Edit the For Each Loop Container, choose the ForEach file enumerator in the Collection window, choose the file path and choose the option Full qualified under retrieve file name. In the variables section choose the variable sFilename and set the index to 0.

In the Data Flow task editor, right click on the Excel Connection Manager,Choose Properties, within the properties choose Expressions. In the Expressions dropdown Choose connection string. In the expression editor window copy and paste the Connection String of Excel connection manager, replace the fully qualified name with the user defined variable. The expression should be like the following:
"Provider=Microsoft.Jet.OLEDB.4.0;Data Source=" + @[User::sFilename]+" ;Extended Properties=\"Excel 8.0;HDR=YES\";"

The backslash in this expression is critical since they are the escape characters. When the evaluate expression is clicked the following statement should appear:
Provider=Microsoft.Jet.OLEDB.4.0;Data Source=C:\Ramdas\SSIS\Sheet1.xls ;Extended Properties="Excel 8.0;HDR=YES";
Once the expression is tested, click ok.
Now going back to the Control Flow the ForEach Container can be executed and multiple files within the source folder would be loaded to the database. In order to make sure that multiple files are loaded one can create an other table in the sql server database and capture the value in the user defined variable into a table.
I would like to thank the author of the blog,Matthew Roche: http:\\bi-polar23.blogspot.com.
Tuesday, August 16, 2011
Left Outer Join...
When one writes complex queries usually there are lot of tables are joined, the query becomes little bit more involved when Left Outer Join or Right Outer Join is involved. In case the query is like a straight left outer join query , the one listed below:
Select Count(*)
From A
Left Join B
On A.AID = B.BID
Where A.AID Is Null
It will always return 0 records if there is no null AID in table A. When a left outer join is involved with other tables which are connected by inner joins, care needs to taken while performing checks like Where A.AID Is Null. I had an issue where a particular query joins and left outer joins was working fine, one fine day after the data was loaded, the query was taking for forever to complete. I was able to find out that the underlying data in the tables had chnaged which caused the query to take a long time. On further analysis in the WHERE clause of the query there was a check for a column to be NULL and this was combined with a OR clause.
It was some thing like : Where A.AID Is Null OR (cond1 and cond2), this was causing the query to run forever. The fix for this was we re-organized the query into 2 parts, the first part of the query runs with a WHERE clause checking for null, the second query runs with the other conditions listed after the OR clause. This caused the query to speed up tremendously and gave us the desired results.
In short when having complex queries and left outer joins it is best to test the queries with different variations of data to make sure the query returns the desired results.
Select Count(*)
From A
Left Join B
On A.AID = B.BID
Where A.AID Is Null
It will always return 0 records if there is no null AID in table A. When a left outer join is involved with other tables which are connected by inner joins, care needs to taken while performing checks like Where A.AID Is Null. I had an issue where a particular query joins and left outer joins was working fine, one fine day after the data was loaded, the query was taking for forever to complete. I was able to find out that the underlying data in the tables had chnaged which caused the query to take a long time. On further analysis in the WHERE clause of the query there was a check for a column to be NULL and this was combined with a OR clause.
It was some thing like : Where A.AID Is Null OR (cond1 and cond2), this was causing the query to run forever. The fix for this was we re-organized the query into 2 parts, the first part of the query runs with a WHERE clause checking for null, the second query runs with the other conditions listed after the OR clause. This caused the query to speed up tremendously and gave us the desired results.
In short when having complex queries and left outer joins it is best to test the queries with different variations of data to make sure the query returns the desired results.
Tuesday, August 9, 2011
SQL Server Collation...
SQL Server Collation is a setting which usually gets set at the time of SQL Server Installation. At the time of database restores from backups which have been taken from other SQL Servers there could be collation mismatches. This could lead sometime to errors like this:
Msg 468, Level 16, State 9, Line 1
Cannot resolve the collation conflict between "SQL_Latin1_General_Pref_CP437_CI_AS" and "SQL_Latin1_General_CP850_BIN" in the equal to operation.
One needs to check certain aspects like collation before doing a restore. Usually the server collation is the baseline, the tempdb follows the SQL Server Collation. A database on a server could be of a different collation from the Server Collation. In order to check the collation of the databases one can run the following query:
select name, collation_name from sys.databases.
The SQL Server Collation can be checked by right clicking on the server and click properties:

Msg 468, Level 16, State 9, Line 1
Cannot resolve the collation conflict between "SQL_Latin1_General_Pref_CP437_CI_AS" and "SQL_Latin1_General_CP850_BIN" in the equal to operation.
One needs to check certain aspects like collation before doing a restore. Usually the server collation is the baseline, the tempdb follows the SQL Server Collation. A database on a server could be of a different collation from the Server Collation. In order to check the collation of the databases one can run the following query:
select name, collation_name from sys.databases.
The SQL Server Collation can be checked by right clicking on the server and click properties:

Friday, August 5, 2011
Data Viewer (SSIS)...
When designing and testing on data flow task, one of the aspects that is tested is how the data is getting from source to destination data source. While testing the SSIS packages one might encounter issues in the data flow task, one of the options available is the Data Viewer. This option can be chosen in the data flow task of an SSIS package. With the Data flow task, right click on the connector which connects the source and destination data sources. Choose the Data Viewer Option, this would open up the Data Flow Path Editor.

On the left side of the window there is a option for Data Viewer, highlight it and click the Add button. This would open up the Configure Data Viewer Window. This window has two tabs General and Grid. In the General tab one can choose from four types:
Grid,Histogram,Scatter Plot(x,y),Column Chart.
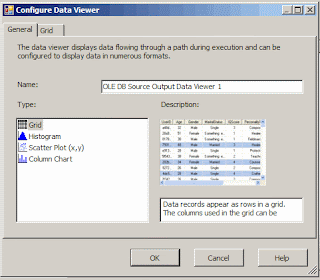
Except for the Grid option the other three options give an idea o\about the data in a graphical format. In the Grid tab one can configure what columns need to be displayed in the Data Viewer. Once the columns are chosen and click the OK button and exit out of the data flow path editor, the data viewer is ready for use. When the data flow executes the configured data viewer pops up with the column headings and data in a grid.
DataViewer Popup window:


On the left side of the window there is a option for Data Viewer, highlight it and click the Add button. This would open up the Configure Data Viewer Window. This window has two tabs General and Grid. In the General tab one can choose from four types:
Grid,Histogram,Scatter Plot(x,y),Column Chart.

Except for the Grid option the other three options give an idea o\about the data in a graphical format. In the Grid tab one can configure what columns need to be displayed in the Data Viewer. Once the columns are chosen and click the OK button and exit out of the data flow path editor, the data viewer is ready for use. When the data flow executes the configured data viewer pops up with the column headings and data in a grid.
DataViewer Popup window:

Wednesday, July 27, 2011
SSIS-Transfer SQL Server Objects...
I was working on a project where in i had to convert the DTS packages which copied data from source tables into destination tables (both SQL Server Databases) into SSIS packages. One of the tasks used in the SSIS package was the Transfer SQL Server Objects task. In this task certain tables had to be copied from source Sql Server DB to Destination Database. In the Transfer SQL Server Objects task editor (this can be opened by highlighting the task, right click on it and choose the Edit... Option), there is an option called TableList Under the ObjectsToCopy Section which is under the Destination Copy Options ( which is part of the Objects Section). When one clicks on the three dots one can see the table list and the tables that need to be copied can be checked.
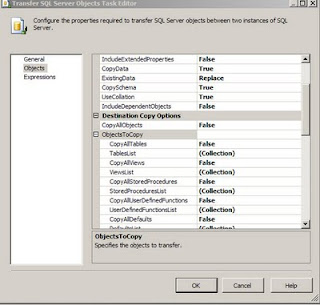
In case the number of tables is large and in case one wants to find out which tables have been choosen to be copied over, there is easier way to look at the members in the table collection. One has to highlight the Transfer SQL Server Objects task and right click and choose properties. In the list of properties choose the TableList under the Misc Category and click on the three dots, one gets to see the following window which shows the tables that have been selected, for the purpose of confidentiality i have erased the table names in the graphic.
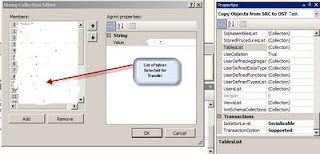
I wanted to highlight the use of properties for this task to view the Collection of the tables.
In case the number of tables is large and in case one wants to find out which tables have been choosen to be copied over, there is easier way to look at the members in the table collection. One has to highlight the Transfer SQL Server Objects task and right click and choose properties. In the list of properties choose the TableList under the Misc Category and click on the three dots, one gets to see the following window which shows the tables that have been selected, for the purpose of confidentiality i have erased the table names in the graphic.
I wanted to highlight the use of properties for this task to view the Collection of the tables.
Thursday, July 21, 2011
High Availabilty...
In continuation with my post regarding Production server being down, I am evaluating possible High availability options, here are some key points. There are lot of discussions on MSDN and there are blogs which explore this deeper.
I have listed some points here.
I have listed some points here.
Both Log shipping and Mirroring have two copies of same db, ( Log shipping can have many copies) , but the secondary dbs are READ only, unlike the contingency dbs, this can be modified.
Log shipping backup T- log interval will determine data-lose risk, for example, if we backup T- log file every 5 minutes, there might be loss of data within 5 min.
Mirror is the latest SQL technology, it requires more hardware resource, especially network bandwidth, The Mirror can be configured to insure no data-lose during disaster, but performance will be little low.
Cluster is for high availability (least downtime) for SQL server instance, also if active/active cluster is used one can get better performance, but it needs Windows clusters. Cluster itself is not for disaster recovery,(it only has one copy of all dbs). One can use Redundancy Disk Array to prevent disk failure.
One can also can combine with logshipping and cluster together to get both high availability and disaster recovery.
Log shipping/Mirroring provide database level high availability, so objects like logins, linked server, Jobs, SSIS packages have to be manually created on secondary servers. One of the parameters that need to be considered for Log Shipping and mirroring is also the proximity of the failover server, if this is in a far off place there could be some issues with how soon the failover server can take over.
Cluster provides server level high availability, so no need to worry about logins, linked server, Jobs, SSIS packages.
Cluster provides server level high availability, so no need to worry about logins, linked server, Jobs, SSIS packages.
Wednesday, July 20, 2011
SQL Server Denali CTP3...
Microsoft has released the CTP3 version of SQL Server Denali, yet to get around and install this version. Here are a couple of links talking about SQL Server Denali CTP3.
As per MSDN article:
SQL Server Code Name “Denali” is a cloud-ready information platform that will help organizations unlock breakthrough insights across the organization and quickly build solutions to extend data across on-premises and public cloud backed by mission critical confidence
http://www.microsoft.com/sqlserver/en/us/future-editions.aspx.
http://redmondmag.com/articles/2011/07/13/microsoft-releases-sql-server-denali-ctp3.aspx
As per MSDN article:
SQL Server Code Name “Denali” is a cloud-ready information platform that will help organizations unlock breakthrough insights across the organization and quickly build solutions to extend data across on-premises and public cloud backed by mission critical confidence
http://www.microsoft.com/sqlserver/en/us/future-editions.aspx.
http://redmondmag.com/articles/2011/07/13/microsoft-releases-sql-server-denali-ctp3.aspx
Monday, July 11, 2011
Failover Database Server...
I ran into a issue last week where in the main production server went down in the morning and it threw off all our key processing. We were dead in the water for 2-3 hours and then the contingency server had to be used but then the data on this server was not current. A process of restoring database on the contingency server had to be undertaken and by the time the contingency server was up and running with the latest production data one full day had been lost and the processing and the reports that had to be generated were not complete. There was another set of tasks which had to be undertaken to complete the lost day's processing and bring all the data upto date. When the experts were called to troubleshoot the issue with the database production server, first there were some patches applied and then there were attempts to reboot the server which failed. On further analysis it was found that there were some HBA cards which were faulty which caused the server and SAN communication to breakdown. I am still not sure what the exact cause link here is between the SAN and the server to go down. There were lessons learnt because of this server failure, one is to have a failover server which would take over if the Primary goes down. I am working on putting together an environment where the contingency is as close to production as possible in terms of data and setup. This kind of server shutdown caused a lot of lost hours for the line of business and also there was lot of stress and conflict. I hope to avoid such a situation by more thoughtful planning and implementation.
Thursday, May 12, 2011
SSIS 2008-Data Conversion...
Recently I was working on getting data from a Excel spreadsheet into a Sql Server table. The excel sheet had the column names in the first row and the data set was medium in size in sense that it was about a few thousand rows. I built a SSIS package with a Data flow task which had a Excel Data Source and a OLE DB Destination for the Sql Server Database. I set up the data flow task with the mappings and did a test run of the SSIS package. During the execution there were data loading errors due to data type issues. On further research i found that the data type on excel spreadsheets were of UNICODE type and these were getting into non-unicode columns on the Sql Server table and this caused the error. In order to fix this issue I used the data conversionn task. The data conversion task is available in the data flow editor and usually sits after the source data connection. This means that the output of the source data is connected with the Data conversion task. Right click on the data conversion task and choose edit, this brings up a window which shows the list of columns in the data source. One check on the columns that need to be converted from to unicode to non-unicode. Here is a snapshot of the data conversion task editor: First Choose the input column, then rename the output alias if needed, then choose the non-unicode data type you want the source data to be converted to, repeat the steps for all the input columns that are selected and then click ok.

Once the Data conversion task editing is complete, connect it to the ole db destination. Here is an illustration of the data flow task with the Data Conversion task included.
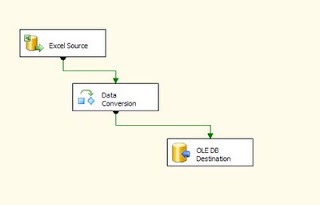

Once the Data conversion task editing is complete, connect it to the ole db destination. Here is an illustration of the data flow task with the Data Conversion task included.

Tuesday, May 3, 2011
Splitting Queries...
I ran into a issue with a query which was running very slow. The query was returning only two columns but there was join between six to seven tables. When we had to move to a different server for development, the performance of the query went down even further. On examining the query, i found certain conditions in the where clause which were being repeated, also there were two conditions as part of the where clause which were linked by a OR condition like . One of the approaches i took was that I took the query with the seven table join and split it into two queries. I re-ran the query after the split and the performance greatly improved, it was taking 30 mins to execute when it was one big query. After the split i got the same results and execution time was 3 minutes. In a nutshell where there are lot of tables say more than 4 being joined, one needs to analyze the query and see if the results can be achieved in a faster manner in case the performance is bad.
Friday, April 29, 2011
Feature...
When a query is executed in sql server 2005 management studio, the results when show in grid format has the headers and results. When one wants to copy the results to excel, it does not copy the headers by default in sql 2005. In sql server 2008 there is options in the results which says copy the results with headers. In order to achieve the effect, there is an option in sql server 2005 management studio to copy results with the headers. Below is a screen shot: Once the option is set when the results are displayed in grid format, the data can be copied with headers to excel.


Monday, April 18, 2011
Performance Tuning-Continued...
As part of the Performance tuning exercise, one of the options that can be experimented with is the sp_configure 'max degree of parallelism' option. This options is an advanced option, in order to set the advanced options do the following:
sp_configure 'show advanced options', 1;
GO
RECONFIGURE WITH OVERRIDE;
GO
Once the above is done, run the following script:
sp_configure 'max degree of parallelism',0;
GO
RECONFIGURE WITH OVERRIDE;
GO
In the above script the value of max degree of parallelism is set to zero, which means that tell sql server to use all available processors. Any value other than zero can be set upto to the available number of processors.
Once can override the values of degree of parallelism by specifying the MAXDOP query hint in the query statement.
sp_configure 'show advanced options', 1;
GO
RECONFIGURE WITH OVERRIDE;
GO
Once the above is done, run the following script:
sp_configure 'max degree of parallelism',0;
GO
RECONFIGURE WITH OVERRIDE;
GO
In the above script the value of max degree of parallelism is set to zero, which means that tell sql server to use all available processors. Any value other than zero can be set upto to the available number of processors.
Once can override the values of degree of parallelism by specifying the MAXDOP query hint in the query statement.
Wednesday, April 13, 2011
Performance Tuning...
One of the issues as a Sql server architect/developer faces constantly is performance issues of queries/applications on the SQL Server database. There are lot of ways to do performance tuning, here in this post I would like to highlight some of the steps in approaching performance issues. They performance can be seperated into two broad aspects, one would be the system/hardware resources aspect, the other would be the programming/query aspect. In other words the methodology would comprise of (1) checking/configuring system resources, and (2) tuning individual queries. Let us focus on the query/programming aspect. When optimizing a query, the following tools can be used: The options can be set before the actual query block.
1. SET STATISTICS IO ON
2. SET SHOWPLAN_XML ON
3. SET SHOWPLAN_TEXT ON
In the Manangement Studio, the Display Estimated Execution Plan and Include Actual Execution Plan can be used. While looking at the execution plans look out of table scans followed by clustered index scans and index scans. On interpreting the Statistics IO, look at the Logical reads, Physical reads parameters, also look at if there are any read-aheads.
The following Option can be used to check the index fragmentation on a table:
DBCC SHOWCONTIG('TestTable', 'TempIndx')
The following option can be used to Display the current distribution statistics for the specified target on the specified table.
DBCC SHOW_STATISTICS('TestTable','TempIndx')
UPDATE STATISTICS can be used to keep the statistics of the table up to date.
Some of the basic parameters that can be monitored on the System/Hardware side:
CPU Utilization. ( How much is CPU pressured, On an average when the CPU utilization starts getting over 60-70% range and starts following this pattern,one needs to pay attention to such instances)
Memory Utilization (How much of meroy is reserved for SQL Server).
Disk I/O and Network I/O rates.
In this post I have listed some basic steps towards Performance tuning, in future articles, I would attempt to post more detailed information on the performance tuning steps.
1. SET STATISTICS IO ON
2. SET SHOWPLAN_XML ON
3. SET SHOWPLAN_TEXT ON
In the Manangement Studio, the Display Estimated Execution Plan and Include Actual Execution Plan can be used. While looking at the execution plans look out of table scans followed by clustered index scans and index scans. On interpreting the Statistics IO, look at the Logical reads, Physical reads parameters, also look at if there are any read-aheads.
The following Option can be used to check the index fragmentation on a table:
DBCC SHOWCONTIG('TestTable', 'TempIndx')
The following option can be used to Display the current distribution statistics for the specified target on the specified table.
DBCC SHOW_STATISTICS('TestTable','TempIndx')
UPDATE STATISTICS can be used to keep the statistics of the table up to date.
Some of the basic parameters that can be monitored on the System/Hardware side:
CPU Utilization. ( How much is CPU pressured, On an average when the CPU utilization starts getting over 60-70% range and starts following this pattern,one needs to pay attention to such instances)
Memory Utilization (How much of meroy is reserved for SQL Server).
Disk I/O and Network I/O rates.
In this post I have listed some basic steps towards Performance tuning, in future articles, I would attempt to post more detailed information on the performance tuning steps.
Thursday, April 7, 2011
Linked Servers...
For one of the projects I am working on right now, I had to create Linked servers in my development and QA environments. The requirement was that the remote servers were different in Dev and QA but the name of the linked server had to be the same name in Dev and QA environments. When one adds a linked server where the remote server is sql server, there are two options for server type. The first server type is SQL Server, the second option is Other data Source. In the first option one has to put in the remote server name( this is the actual sql server name), then click on Security in the Linked Server properties window. In the Security screen, one needs to enter the security context: this screen defines how one is going to login to the remote server. Once this done and you click OK, the linked server will be created, at the same time it also tests the connection to the remote server.
In the second option Other data Source, one has to choose the type of remote server ( sql server, oracle etc...) and then provide the Product Name,Data Source and Provider String. In this option one can give a user friendly name for the name of the linked server. This is the option i followed to kep the name of the linked servers consistent across all the Dev and QA servers.

In the second option Other data Source, one has to choose the type of remote server ( sql server, oracle etc...) and then provide the Product Name,Data Source and Provider String. In this option one can give a user friendly name for the name of the linked server. This is the option i followed to kep the name of the linked servers consistent across all the Dev and QA servers.

Tuesday, March 29, 2011
Best Practices...
Recently we we had to move our sql servers from the business unit to the technology unit so that the sql servers could follow certain guidelines and best practices. When the move happened and I was ready to test sql scripts on the new sql servers which follow certain guidelines to handle security,user access and what is allowed/not allowed with respect to database objects. While I was performing the tests I ran into some errors and noticed that i was missing some scalar functions, on further inspection the functions were supposed to be available on the master database. I raised a flag here and noted that custom user defined functions and stored procedures had been created on the master database on the older sql server's. When database development was done on these servers obviously certain guidelines and standards were not followed. Lack of adhering to standards ended up creating a clean up project which involved moving the custom user defined database/stored procedures from the master database to the user defined database. Based on what i have read/listened to in sql server classes, one should avoid creating custom user defined functions and stored procedures on the system databases of sql server such as master,msdb and tempdb. It is always a good idea to follow/enforce certain guidelines while working on database development projects.
Monday, March 7, 2011
Mobile BI...
The paradigm of computing keeps changing, in the last couple of years there were new platform which have made in roads and are in process of becoming firmly established. Platforms like cloud computing, mobile frameworks such as smartphones,tablets are continuing to grow, given this perspective it seems like BI is moving into mobile space. Microstrategy has come out in a big way by making BI available on the ipad at the same time direction from Microsoft in this space is not very clear. It is kind of interesting because Microsoft is now pushing windows phone 7. There are other vendors who have come out with BI offerings for the mobile platform. Here are a couple of vendors which i have researching and going through the offerings.
RoamBI: http://www.roambi.com/, the second vendor i am looking at is: http://www.pushbi.com/. I am looking to attend some free webcasts to get an idea of the products. I also questions in mind as to how much value can BI on mobile platform can offer to the Business user.
RoamBI: http://www.roambi.com/, the second vendor i am looking at is: http://www.pushbi.com/. I am looking to attend some free webcasts to get an idea of the products. I also questions in mind as to how much value can BI on mobile platform can offer to the Business user.
Friday, February 25, 2011
SQL Server (Denali)-CTP1
I downloaded the SQL Server Denali CTP1 version fro MSDN and began the installation process. The first thing i came across was that my OS was not up to the required level. I found out based on the requirements that if one has vista then SP2 needs to be applied. Once the SP2 was accomplished went through the setup process. It was very similar to the setup of sql server 2008 R2 version. On completion of the setup launched the Management studio, in the splash screen it displayed Powered by Visual Studio at the right hand corner. It gave an indication that the UI of SSMS is going to be more tied in with visual studio 2010. I have just begun to play around with queries in Denali,one of features that has been enhanced is Intellisense, there are more options in the Intellisense menu. I will planning to provide more updates as i explore the features of Denali. I also installed the BIDS, Integration services and reporting services components of denali.
Tuesday, February 22, 2011
Tutorial Articles...SQL Server
One of the sql server community sites which i read and visit frequently is http://www.sqlservercentral.com. There are lots of articles and tutorials on different aspects of sql server written by SQL Server Experts and SQL Server MVP's. I have learnt a lot about SQL Server from sqlservercentral.com. One of the interesting and helpful series put together recently has been the Kalen Delaney's SQL Server Stairways series, here is the link: http://www.sqlservercentral.com/stairway/. The series helps to keep up to date with all the technologies in SQL Server, the DBA or developer who wants to stay ahead is faced with the struggle of constant learning.
Wednesday, February 16, 2011
SSRS-Report Portal...
I recently installed SQL Server 2008 on my laptop which included SSAS,SSIS and SSRS. I installed SSRS in the native mode configuration. I had to work on developing reports in SSRS and deploy the reports. I developed the Reports in BIDS and was ready to deploy the reports on my localhost report portal. When I tried to deploy the reports i got an error saying my account did not have access to the portal. I launched Internet Explorer as an Administrator and I was able to get to my localhost report portal. Once i got to the site, there were two tabs contents and properties. I clicked on the properties tab and added my account as a Content manager and saved the settings. Once this was complete, I went back to BIDS and deployed the report, the report was successfully deployed to my report portal.
Tuesday, February 8, 2011
Error Handling...
One of the aspects in T-SQL development, especially with writing stored procedures is Error Handling. It is important to trap errors, log the errors and provide a proper exit from a stored procedure. One of concepts which was introduced in the .NET framework, has been incorporated into T-SQL. It is the BEGIN TRY..END TRY and BEGIN CATCH..END CATCH block. this feature allows one to keep the code blocks within the stored procedure modular. Here is an example of the use of TRY CATCH block within the stored procedure.
BEGIN TRY
INSERT INTO tablea
(col1,col2,col3)
SELECT col1,col2,col3 FROM testtable
END TRY
BEGIN CATCH
INSERT INTO table_error_log
ErrorNumber,ErrorSeverity,ErrorState,ErrorProcedure,ErrorLine,ErrorMessage)
SELECT ERROR_NUMBER() AS ErrorNumber,
ERROR_SEVERITY() AS ErrorSeverity,
ERROR_STATE() as ErrorState,
ERROR_LINE () as ErrorLine,
ERROR_PROCEDURE() as ErrorProcedure,
ERROR_MESSAGE() as ErrorMessage
END CATCH
One of the neat things while using the CATCH block is the availability certain standard functions which provides the Error Procedure and Error Message. These functions can provide valueable information about the Error.
BEGIN TRY
INSERT INTO tablea
(col1,col2,col3)
SELECT col1,col2,col3 FROM testtable
END TRY
BEGIN CATCH
INSERT INTO table_error_log
ErrorNumber,ErrorSeverity,ErrorState,ErrorProcedure,ErrorLine,ErrorMessage)
SELECT ERROR_NUMBER() AS ErrorNumber,
ERROR_SEVERITY() AS ErrorSeverity,
ERROR_STATE() as ErrorState,
ERROR_LINE () as ErrorLine,
ERROR_PROCEDURE() as ErrorProcedure,
ERROR_MESSAGE() as ErrorMessage
END CATCH
One of the neat things while using the CATCH block is the availability certain standard functions which provides the Error Procedure and Error Message. These functions can provide valueable information about the Error.
Wednesday, January 26, 2011
Rename .MDF File...
I have been working on a project where the database files had to be rename. The name of the files had to be consistent with the database. Initially I detached the database, renamed the files in Explorer, then tried to re-attach the database, I was getting an error. I came across the following steps (thanks to MSDN news groups) and implemented them, the renaming of the database worked well. This was done on SQL Server Version 2008 R2. In the example the db.mdf and db.ldf file will point to the newly named files.
Note: The following feature does not work in SQL Server 2000.
ALTER DATABASE databaseName SET OFFLINE
GO
ALTER DATABASE databaseNAme MODIFY FILE (NAME =db, FILENAME = 'C:\Program
Files\Microsoft SQL Server\MSSQL.2\MSSQL\Data\db.mdf')
GO
--if changing log file name
ALTER DATABASE databaseNAme MODIFY FILE (NAME = db_log, FILENAME =
'C:\Program Files\Microsoft SQL Server\MSSQL.2\MSSQL\Data\db.ldf')
GO
--Before you set the database online , you would have to manually change the filename at the OS level.
--Failing on this part will not let you to start up the database.
ALTER DATABASE databaseName SET ONLINE
GO
Note: The following feature does not work in SQL Server 2000.
ALTER DATABASE databaseName SET OFFLINE
GO
ALTER DATABASE databaseNAme MODIFY FILE (NAME =db, FILENAME = 'C:\Program
Files\Microsoft SQL Server\MSSQL.2\MSSQL\Data\db.mdf')
GO
--if changing log file name
ALTER DATABASE databaseNAme MODIFY FILE (NAME = db_log, FILENAME =
'C:\Program Files\Microsoft SQL Server\MSSQL.2\MSSQL\Data\db.ldf')
GO
--Before you set the database online , you would have to manually change the filename at the OS level.
--Failing on this part will not let you to start up the database.
ALTER DATABASE databaseName SET ONLINE
GO
Friday, January 21, 2011
DTS Package on 64 bit SQL Server.
I was working on a server migration project and part of the migration was to move the DTS packages to the new SQL Server. Once the DTS packages were copied over, I started testing the DTS packages. The jobs which ran the DTS packages failed, the error was related to connecting to the source sql server from where the data was being copied. Did some research and found with the help of my colleague that DTS which is 32 bit is running on a 64 bit sqlserver. The DTS packages are 32 bit code and hence look for a 32 bit alias in order to resolve the server name. In order to solve the issue we had to create a 32 bit alias under SQL Native Configuration in the SQL Server Configuration Manager. There are 2 SQL Native Client Configuration available 32 bit and 64 bit, in order to solve the issue with DTS, i had to create 32 bit aliases. It was an interesting challenge i ran into and it took me a while to get the hang of the issue, at the beginning i did not have 32 bit vs 64 bit issues in mind.
Thursday, January 13, 2011
SSIS - Access Mode...
I was working on a fairly simple SSIS package, as part of the package I had to move data from a SQL Server Database to another SQL Server Database. I used a Data Flow to do a simple copy of the data using OLE DB Source and Destination. When I executed the package, I found that the performance of the Data Copy was very slow. What was puzzling was that the number of rows to be copied were just around 1000 rows and the table was not very wide. Based on research from other blogs, there is a property called Access Mode in the OLE DB Destination Data Flow component. I Set the AccessMode to OpenRowset Using FastLoad and then re-ran the package. The data flow performed the copy of data a lot more faster and the package completed in a much quicker time.
Subscribe to:
Posts (Atom)