In continuation with my earlier blog post of type 1 and type 2 dimensions, there is a third type called the type 3 dimension. The type 3 dimension has limited history preservation in the sense that the history of data is maintained by adding new columns to store historical information. For example if we were to take the example of Manager/Employee as mentioned in y earlier blog post of Type 1 and Type 2, one would have a column called previous endate and a new column called current endate. With this type of construct only the previous history is maintained. I have used a supplier record as an example here.
Supp_Key Sup_Code Supp_Name Start Date Orig_State Curr_State
123 ABC Emp1 22-Dec-2004 TX CA
Employee/Manager Example:
Emp_id Emp_Name Start_Date Orig_Manager_id Current_Mgr_id
235 Emp1 02 Jan 2011 45 55
As one can see in the above schemas it is possible to track only the previous change.
In situations like a Call center when the Structure under a Team manager is dynamic, this would cause lot of additional columns being added to track every change, thus making the table wider and hard to maintain. Type 3 dimensions would find usage where historical changes are limited and the dimension itself is not very volatile.
On a different note, the New Year promises to bring more changes in the area of BigData,Cloud Computing and Social Network/Interactions. It will be interesting to see how the SQL Server EcoSystem adapts/innovates in the above mentioned areas.
I would like to wish all the readers of my blog and everyone a happy and prosperous New Year 2012.
Wednesday, December 28, 2011
Tuesday, December 27, 2011
OLAP basics...
One of the most important aspects of Datawarehousing/Business Intelligence is the aspect of Online Analytical Processing. The key aspects of OLAP are as follows:
Long transactions
Complex queries
Touch large portions of the data
Infrequent updates - Typically in OLAP solutions the data is primarily used for analysis but certain technologies do allow write backs/updates to Cubes. One of the tools which i have worked on which allows such a feature is in Hyperion Essbase where in certain financial cubes one would have the ability to update data in the cube, for example the situation would involve updating budgets for months in a year.
A cube is also known as Multidimensional OLAP. The components of a cube involves the following.
Dimension data forms axes of “cube”
Fact (dependent) data in cells
Aggregated data on sides, edges, corner.
 The above aspects of a cube would help one understand and write better MDX queries which can be typically written to access data from a SSAS cube.
The above aspects of a cube would help one understand and write better MDX queries which can be typically written to access data from a SSAS cube.
There are SQL constructs which would allow one to write queries to examine data, these are provided by the WITH ROLLUP and WITH CUBE constructs.
Here is a Sample Query:
Select dim-attrs, aggrtes
From tables
where conditions
Group By dim-attrs With Cube, this would add to result: faces, edges, and corner of cube using NULL values.
Long transactions
Complex queries
Touch large portions of the data
Infrequent updates - Typically in OLAP solutions the data is primarily used for analysis but certain technologies do allow write backs/updates to Cubes. One of the tools which i have worked on which allows such a feature is in Hyperion Essbase where in certain financial cubes one would have the ability to update data in the cube, for example the situation would involve updating budgets for months in a year.
A cube is also known as Multidimensional OLAP. The components of a cube involves the following.
Dimension data forms axes of “cube”
Fact (dependent) data in cells
Aggregated data on sides, edges, corner.

There are SQL constructs which would allow one to write queries to examine data, these are provided by the WITH ROLLUP and WITH CUBE constructs.
Here is a Sample Query:
Select dim-attrs, aggrtes
From tables
where conditions
Group By dim-attrs With Cube, this would add to result: faces, edges, and corner of cube using NULL values.
Tuesday, December 20, 2011
SSIS-sysssispackages...
I am working on a project where there are lot of ssis packages that need to be converted to SSIS 2008. One of the steps involved in the project is to test the SSIS packages after conversion. In order to test the SSIS packages, the QA folks had to come up with test cases for the SSIS packages, this involved open each SSIS package and identifying areas that need to be checked. It was becoming quite tedious to open and close SSIS packages, at this juncture one of my colleagues suggested a different method to look into the SQL Statements within the SSIS packages. This involved utilising the table sysssispackages which is in the msdb database. The table has columns like Name (SSIS package Name),PackageFormat,PackageType, a complete list of columns is available on Books Online. The column we were interested is called PackageData, this is stored as image in the table. In order to get meaningful information from the PackageData column, the data in the column had to be converted to VARBINARY and then to XML. Here is the query:
SELECT Name, CONVERT(xml,CONVERT(varbinary(max),PackageData)) AS PackageSource
FROM msdb.dbo.sysssispackages
The query produces result like the following:
 I have masked the names of the SSIS packages due to confidentiality, as one can see a hyperlink XML data in the Column named PackageSource. In order to completly view the XML one has to click on the link. This action will open up a new tab within SSMS and the complete XML of the package can be viewed. In this document one can then perform regular string searches to locate SQL statements. We are still working on how effective this approach would be in comparison with opening and closing each SSIS package in the context of searching for SQL statements. I just want to share with you as how to decrypt the PackageData Column.
I have masked the names of the SSIS packages due to confidentiality, as one can see a hyperlink XML data in the Column named PackageSource. In order to completly view the XML one has to click on the link. This action will open up a new tab within SSMS and the complete XML of the package can be viewed. In this document one can then perform regular string searches to locate SQL statements. We are still working on how effective this approach would be in comparison with opening and closing each SSIS package in the context of searching for SQL statements. I just want to share with you as how to decrypt the PackageData Column.
SELECT Name, CONVERT(xml,CONVERT(varbinary(max),PackageData)) AS PackageSource
FROM msdb.dbo.sysssispackages
The query produces result like the following:

Thursday, December 15, 2011
SSIS-Fast Load
In SSIS, as part of the data flow the OLE DB Destination Component is used to insert records into a table in a SQL Server database. There quite a few strategies that can be adopted while loading data into a table.
In the OLEDB Destination Component properties there are different AccessMode, one of them is called OpenRowSet Using Fast Load option. When this option is set one gets to work with other FastLoad Properties such as:
FastLoadKeepIdentity
FastLoadKeepNulls
FastLoadOptions
FastLoadMaxInsertCommitSize
When doing a Fastload, the FastLoadMaxInsertCommitSize is Set to 0, this means that the insert into a table is done has one transaction and then a Commit is applied for the transaction. The reason why this value has to be managed is because when the number of rows being inserted are huge (say a million/millions), it would be wise to break up the transaction into a smaller number of rows per insert. The other reason for having smaller transactions is also being able to manage the log effectively. There is also a note from MSDN noted below:
From MSDN:
A value of 0 might cause the running package to stop responding if the OLE DB destination and another data flow component are updating the same source table.
To prevent the package from stopping, set the Maximum insert commit size option to 2147483647.
In Summary, while using FastLoad option one needs to aware of what kind of load is being performed in terms of number of records and then tune the fast load options to work effectively.
In the OLEDB Destination Component properties there are different AccessMode, one of them is called OpenRowSet Using Fast Load option. When this option is set one gets to work with other FastLoad Properties such as:
FastLoadKeepIdentity
FastLoadKeepNulls
FastLoadOptions
FastLoadMaxInsertCommitSize
When doing a Fastload, the FastLoadMaxInsertCommitSize is Set to 0, this means that the insert into a table is done has one transaction and then a Commit is applied for the transaction. The reason why this value has to be managed is because when the number of rows being inserted are huge (say a million/millions), it would be wise to break up the transaction into a smaller number of rows per insert. The other reason for having smaller transactions is also being able to manage the log effectively. There is also a note from MSDN noted below:
From MSDN:
A value of 0 might cause the running package to stop responding if the OLE DB destination and another data flow component are updating the same source table.
To prevent the package from stopping, set the Maximum insert commit size option to 2147483647.
In Summary, while using FastLoad option one needs to aware of what kind of load is being performed in terms of number of records and then tune the fast load options to work effectively.
Monday, December 12, 2011
SSIS-SCD Type 1 & Type 2
One of the important tasks in an ETL process which supports a Datawarehouse/DataMart is to load data into dimension tables. As per Kimball methodology there are three types of Dimensions like type 1, type 2 and type 3. The most discussed and often implemented is the Type 1 and Type 2 Dimensions. To get a quick overview of the two types: Type 1 dimensions are usually static, in case there are updates the old values are just overwritten. In case Type 2 or slowly changing dimension there is usually a historical record of what changed in the Dimension. A good example of this could agents working for a Team Manager in a Call center. A agent could have his Team Manager re-assigned and this change would have to captured in the data mart and that is where Type 2 dimensions come in. In SSIS in order to facilitate the loads of Type 1 and Type 2 dimensions, we have the SCD wizard which can be used. On walking through the wizard, one can set up Changing attributes and Historical attributes. Once this task is finished, a data flow is generated to handle Type 1 and Type 2 Dimension loading. In the image below one can notice the OLE DB Command Component being used by SCD component.
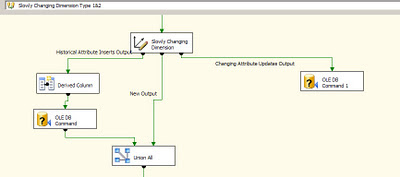
As it has been discussed in a lot of articles,blogs, the SCD component does not scale very well. There have been performance issues with using the SCD component straight out of the box. One of reasons could be the fact that the SCD component uses the OLE DB Command component to perform updates of rows, these rows are updated one row at a time. The time to update the rows can significantly increase if there are a lot of changes that are to be processed. In fact even while performing incremental inserts or updates to tables in general OLE DB command component can take up quite a bit of time in order to process the rows.
One of the methods to alleviate performance is to use a temporary/staging table where in all the changes are loaded in the destination database. Once this data flow is complete, use a stored procedure to merge the changes into the actual destination table. In the Stored procedure one could take advantage of the MERGE T-SQL command to insert/update records into the destination table by using the temporary/staging table. In the image below one can notice that the OLE DB Command component has been replaced by the OLE DB Destination component.
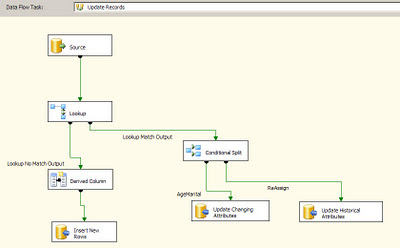


As it has been discussed in a lot of articles,blogs, the SCD component does not scale very well. There have been performance issues with using the SCD component straight out of the box. One of reasons could be the fact that the SCD component uses the OLE DB Command component to perform updates of rows, these rows are updated one row at a time. The time to update the rows can significantly increase if there are a lot of changes that are to be processed. In fact even while performing incremental inserts or updates to tables in general OLE DB command component can take up quite a bit of time in order to process the rows.
One of the methods to alleviate performance is to use a temporary/staging table where in all the changes are loaded in the destination database. Once this data flow is complete, use a stored procedure to merge the changes into the actual destination table. In the Stored procedure one could take advantage of the MERGE T-SQL command to insert/update records into the destination table by using the temporary/staging table. In the image below one can notice that the OLE DB Command component has been replaced by the OLE DB Destination component.

To finish this up, in the contro flow we would have a Execute SQL task to perform the Merge operation. Here is a visual of the Flow.

Monday, December 5, 2011
BigData,NoSQL...
In the recent couple of years there has been steady development in areas of non-relational data storage, where in the data does not fit into a more orderly schema instead the data tends to have flexible schema. These center around the recent developments in social media and social networking where in enormous amounts of data is being stored and retrieved. Since the vendors/companies in social networking space did not find traditional RDBMS to suit their needs, the emergence of NoSQL systems took place. NoSQL means "Not only SQL". These systems (NoSQL) have flexible schema,Massive scalability (since lot of requests can be handled in parallel) and higher performance and availability. There are different implementations of NoSQL Systems, they are:
1. MapReduce FrameWork.
2. Key-Value Stores
Example Systems: Google BigTable,Amazon Dynamo,Cassandra.
3. Document Stores.
Example Systems: CouchDB,MongoDB,SimpleDB.
4. Graph Database Systems.
Example Systems: Neo4j,FlockDB,Pregel.
The MapReduce Framework is kind of analogous to OLAP in the Business Intelligence world, the Key-Value Stores can be kind of analogous to the OLTP world. Document Stores use a Key,Document pair to persist documents and also enables faster retrieval of documents, one of the popular systems which implements Document Store is MongoDB.
One of the popular implementation of NoSQL system is the MapReduce Framework which was originally developed in Google, then followed by the Open Source implementation called Hadoop. This Map Reduce has No Data model, the data is stored in files on the Google File System (GFS) or the Hadoop file System called HDFS. There are specific functions in this Framework such as Map(),Reduce(),Reader(),Writer() and Combiner(). Microsoft has plans to work with Hadoop in some form, the NoSQL has been gaining traction in the last couple of years and this space is bound to see a lot of changes in the coming years. I would to thank Prof. Jennifer Widom (Stanford University, Computer Science) for providing information/material on NoSQL Systems as part of a online course in database systems.
1. MapReduce FrameWork.
2. Key-Value Stores
Example Systems: Google BigTable,Amazon Dynamo,Cassandra.
3. Document Stores.
Example Systems: CouchDB,MongoDB,SimpleDB.
4. Graph Database Systems.
Example Systems: Neo4j,FlockDB,Pregel.
The MapReduce Framework is kind of analogous to OLAP in the Business Intelligence world, the Key-Value Stores can be kind of analogous to the OLTP world. Document Stores use a Key,Document pair to persist documents and also enables faster retrieval of documents, one of the popular systems which implements Document Store is MongoDB.
One of the popular implementation of NoSQL system is the MapReduce Framework which was originally developed in Google, then followed by the Open Source implementation called Hadoop. This Map Reduce has No Data model, the data is stored in files on the Google File System (GFS) or the Hadoop file System called HDFS. There are specific functions in this Framework such as Map(),Reduce(),Reader(),Writer() and Combiner(). Microsoft has plans to work with Hadoop in some form, the NoSQL has been gaining traction in the last couple of years and this space is bound to see a lot of changes in the coming years. I would to thank Prof. Jennifer Widom (Stanford University, Computer Science) for providing information/material on NoSQL Systems as part of a online course in database systems.
Friday, December 2, 2011
Visual Studio 2010-SQL
Recently I started using Visual Studio 2010 Professional Version. There are lot of new features in VS 2010 which goes without saying. One of the areas which i frequently work on is databases. There is a lot of integration between VS 2010 and the upcoming SQL Server 2012 version. Once a connection is established to a SQL Server using the server explorer, one can view the objects within the database in the server explorer. In the menu option Data when you choose Transact-SQL Editor, at first you are asked to log in to SQL Server, once logged in the query window opens up just like the one in SQL Server Management studio. There is a option Database next to which one can see the current database you are connected to. This feature comes in handy when there is development going on in a VS 2010 environment and at the same data needs to be explored. The integration between VS 2010 and SSMS seems very close in VS 2010.

When a query is written, it can highlighted and when the right click on the mouse is pressed, one can see a popup menu being displayed.


When a query is written, it can highlighted and when the right click on the mouse is pressed, one can see a popup menu being displayed.

Subscribe to:
Posts (Atom)