When one writes complex queries usually there are lot of tables are joined, the query becomes little bit more involved when Left Outer Join or Right Outer Join is involved. In case the query is like a straight left outer join query , the one listed below:
Select Count(*)
From A
Left Join B
On A.AID = B.BID
Where A.AID Is Null
It will always return 0 records if there is no null AID in table A. When a left outer join is involved with other tables which are connected by inner joins, care needs to taken while performing checks like Where A.AID Is Null. I had an issue where a particular query joins and left outer joins was working fine, one fine day after the data was loaded, the query was taking for forever to complete. I was able to find out that the underlying data in the tables had chnaged which caused the query to take a long time. On further analysis in the WHERE clause of the query there was a check for a column to be NULL and this was combined with a OR clause.
It was some thing like : Where A.AID Is Null OR (cond1 and cond2), this was causing the query to run forever. The fix for this was we re-organized the query into 2 parts, the first part of the query runs with a WHERE clause checking for null, the second query runs with the other conditions listed after the OR clause. This caused the query to speed up tremendously and gave us the desired results.
In short when having complex queries and left outer joins it is best to test the queries with different variations of data to make sure the query returns the desired results.
Tuesday, August 16, 2011
Tuesday, August 9, 2011
SQL Server Collation...
SQL Server Collation is a setting which usually gets set at the time of SQL Server Installation. At the time of database restores from backups which have been taken from other SQL Servers there could be collation mismatches. This could lead sometime to errors like this:
Msg 468, Level 16, State 9, Line 1
Cannot resolve the collation conflict between "SQL_Latin1_General_Pref_CP437_CI_AS" and "SQL_Latin1_General_CP850_BIN" in the equal to operation.
One needs to check certain aspects like collation before doing a restore. Usually the server collation is the baseline, the tempdb follows the SQL Server Collation. A database on a server could be of a different collation from the Server Collation. In order to check the collation of the databases one can run the following query:
select name, collation_name from sys.databases.
The SQL Server Collation can be checked by right clicking on the server and click properties:

Msg 468, Level 16, State 9, Line 1
Cannot resolve the collation conflict between "SQL_Latin1_General_Pref_CP437_CI_AS" and "SQL_Latin1_General_CP850_BIN" in the equal to operation.
One needs to check certain aspects like collation before doing a restore. Usually the server collation is the baseline, the tempdb follows the SQL Server Collation. A database on a server could be of a different collation from the Server Collation. In order to check the collation of the databases one can run the following query:
select name, collation_name from sys.databases.
The SQL Server Collation can be checked by right clicking on the server and click properties:

Friday, August 5, 2011
Data Viewer (SSIS)...
When designing and testing on data flow task, one of the aspects that is tested is how the data is getting from source to destination data source. While testing the SSIS packages one might encounter issues in the data flow task, one of the options available is the Data Viewer. This option can be chosen in the data flow task of an SSIS package. With the Data flow task, right click on the connector which connects the source and destination data sources. Choose the Data Viewer Option, this would open up the Data Flow Path Editor.

On the left side of the window there is a option for Data Viewer, highlight it and click the Add button. This would open up the Configure Data Viewer Window. This window has two tabs General and Grid. In the General tab one can choose from four types:
Grid,Histogram,Scatter Plot(x,y),Column Chart.
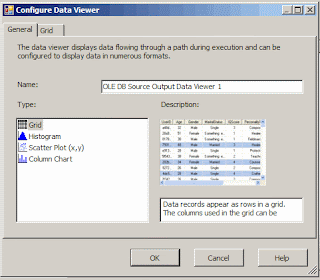
Except for the Grid option the other three options give an idea o\about the data in a graphical format. In the Grid tab one can configure what columns need to be displayed in the Data Viewer. Once the columns are chosen and click the OK button and exit out of the data flow path editor, the data viewer is ready for use. When the data flow executes the configured data viewer pops up with the column headings and data in a grid.
DataViewer Popup window:


On the left side of the window there is a option for Data Viewer, highlight it and click the Add button. This would open up the Configure Data Viewer Window. This window has two tabs General and Grid. In the General tab one can choose from four types:
Grid,Histogram,Scatter Plot(x,y),Column Chart.

Except for the Grid option the other three options give an idea o\about the data in a graphical format. In the Grid tab one can configure what columns need to be displayed in the Data Viewer. Once the columns are chosen and click the OK button and exit out of the data flow path editor, the data viewer is ready for use. When the data flow executes the configured data viewer pops up with the column headings and data in a grid.
DataViewer Popup window:

Wednesday, July 27, 2011
SSIS-Transfer SQL Server Objects...
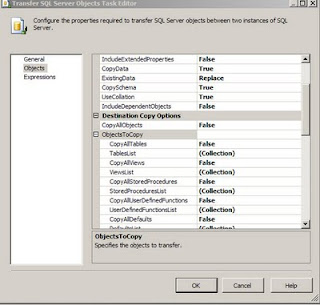
I was working on a project where in i had to convert the DTS packages which copied data from source tables into destination tables (both SQL Server Databases) into SSIS packages. One of the tasks used in the SSIS package was the Transfer SQL Server Objects task. In this task certain tables had to be copied from source Sql Server DB to Destination Database. In the Transfer SQL Server Objects task editor (this can be opened by highlighting the task, right click on it and choose the Edit... Option), there is an option called TableList Under the ObjectsToCopy Section which is under the Destination Copy Options ( which is part of the Objects Section). When one clicks on the three dots one can see the table list and the tables that need to be copied can be checked.
In case the number of tables is large and in case one wants to find out which tables have been choosen to be copied over, there is easier way to look at the members in the table collection. One has to highlight the Transfer SQL Server Objects task and right click and choose properties. In the list of properties choose the TableList under the Misc Category and click on the three dots, one gets to see the following window which shows the tables that have been selected, for the purpose of confidentiality i have erased the table names in the graphic.
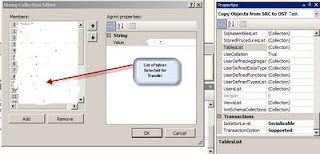
I wanted to highlight the use of properties for this task to view the Collection of the tables.
In case the number of tables is large and in case one wants to find out which tables have been choosen to be copied over, there is easier way to look at the members in the table collection. One has to highlight the Transfer SQL Server Objects task and right click and choose properties. In the list of properties choose the TableList under the Misc Category and click on the three dots, one gets to see the following window which shows the tables that have been selected, for the purpose of confidentiality i have erased the table names in the graphic.
I wanted to highlight the use of properties for this task to view the Collection of the tables.
Thursday, July 21, 2011
High Availabilty...
In continuation with my post regarding Production server being down, I am evaluating possible High availability options, here are some key points. There are lot of discussions on MSDN and there are blogs which explore this deeper.
I have listed some points here.
I have listed some points here.
Both Log shipping and Mirroring have two copies of same db, ( Log shipping can have many copies) , but the secondary dbs are READ only, unlike the contingency dbs, this can be modified.
Log shipping backup T- log interval will determine data-lose risk, for example, if we backup T- log file every 5 minutes, there might be loss of data within 5 min.
Mirror is the latest SQL technology, it requires more hardware resource, especially network bandwidth, The Mirror can be configured to insure no data-lose during disaster, but performance will be little low.
Cluster is for high availability (least downtime) for SQL server instance, also if active/active cluster is used one can get better performance, but it needs Windows clusters. Cluster itself is not for disaster recovery,(it only has one copy of all dbs). One can use Redundancy Disk Array to prevent disk failure.
One can also can combine with logshipping and cluster together to get both high availability and disaster recovery.
Log shipping/Mirroring provide database level high availability, so objects like logins, linked server, Jobs, SSIS packages have to be manually created on secondary servers. One of the parameters that need to be considered for Log Shipping and mirroring is also the proximity of the failover server, if this is in a far off place there could be some issues with how soon the failover server can take over.
Cluster provides server level high availability, so no need to worry about logins, linked server, Jobs, SSIS packages.
Cluster provides server level high availability, so no need to worry about logins, linked server, Jobs, SSIS packages.
Wednesday, July 20, 2011
SQL Server Denali CTP3...
Microsoft has released the CTP3 version of SQL Server Denali, yet to get around and install this version. Here are a couple of links talking about SQL Server Denali CTP3.
As per MSDN article:
SQL Server Code Name “Denali” is a cloud-ready information platform that will help organizations unlock breakthrough insights across the organization and quickly build solutions to extend data across on-premises and public cloud backed by mission critical confidence
http://www.microsoft.com/sqlserver/en/us/future-editions.aspx.
http://redmondmag.com/articles/2011/07/13/microsoft-releases-sql-server-denali-ctp3.aspx
As per MSDN article:
SQL Server Code Name “Denali” is a cloud-ready information platform that will help organizations unlock breakthrough insights across the organization and quickly build solutions to extend data across on-premises and public cloud backed by mission critical confidence
http://www.microsoft.com/sqlserver/en/us/future-editions.aspx.
http://redmondmag.com/articles/2011/07/13/microsoft-releases-sql-server-denali-ctp3.aspx
Monday, July 11, 2011
Failover Database Server...
I ran into a issue last week where in the main production server went down in the morning and it threw off all our key processing. We were dead in the water for 2-3 hours and then the contingency server had to be used but then the data on this server was not current. A process of restoring database on the contingency server had to be undertaken and by the time the contingency server was up and running with the latest production data one full day had been lost and the processing and the reports that had to be generated were not complete. There was another set of tasks which had to be undertaken to complete the lost day's processing and bring all the data upto date. When the experts were called to troubleshoot the issue with the database production server, first there were some patches applied and then there were attempts to reboot the server which failed. On further analysis it was found that there were some HBA cards which were faulty which caused the server and SAN communication to breakdown. I am still not sure what the exact cause link here is between the SAN and the server to go down. There were lessons learnt because of this server failure, one is to have a failover server which would take over if the Primary goes down. I am working on putting together an environment where the contingency is as close to production as possible in terms of data and setup. This kind of server shutdown caused a lot of lost hours for the line of business and also there was lot of stress and conflict. I hope to avoid such a situation by more thoughtful planning and implementation.
Subscribe to:
Posts (Atom)